TL;DR: Запустите цикл «принять — подумать — ответить» на одном вебхуке Whapi.Cloud. Приравняйте thread_id в LangGraph к номеру телефона отправителя и подключите checkpointer — тогда у каждого контакта останется своя память. Возвращайте HTTP 200 меньше чем за секунду, а самого агента запускайте в фоновой задаче. Никакого ngrok, верификации в Meta и шаблонов сообщений. Начните с MemorySaver, а для продакшена замените его на checkpointer на Postgres.
Цикл из трёх шагов, на котором держится любой агент в WhatsApp
ИИ-агент для WhatsApp — это один цикл: принять сообщение, обдумать его агентом с инструментами и отправить ответ. Всё остальное — лишь обвязка вокруг этих трёх шагов.
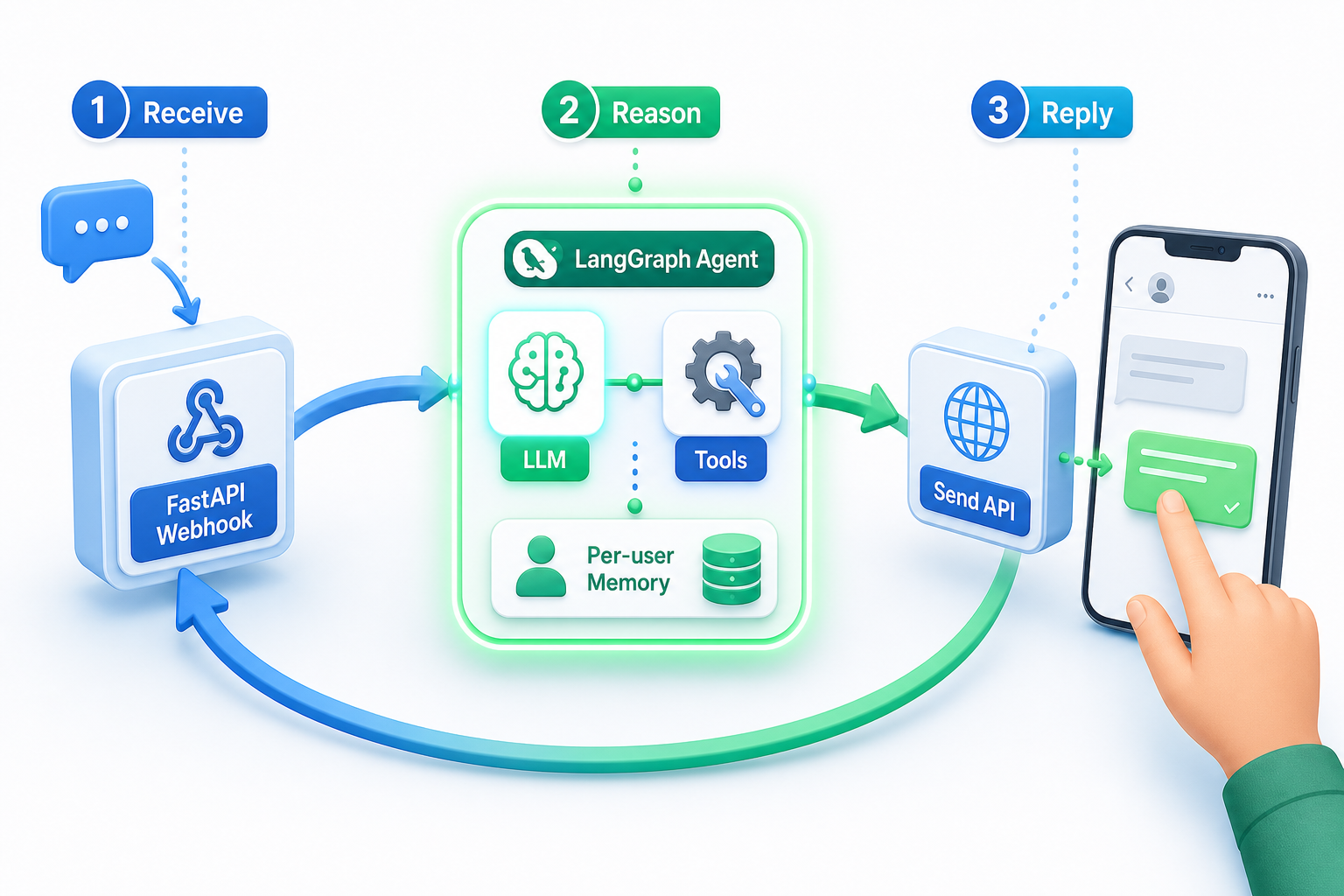
В этой сборке маршрут FastAPI принимает входящее сообщение от Whapi.Cloud, агент LangGraph на базе ChatOpenAI решает, что делать, а один REST-запрос отправляет ответ обратно. Номер телефона, с которого вам написали, — единственный идентификатор, который нужно протащить через все три шага.
Подключите номер и направьте один вебхук на ваше приложение
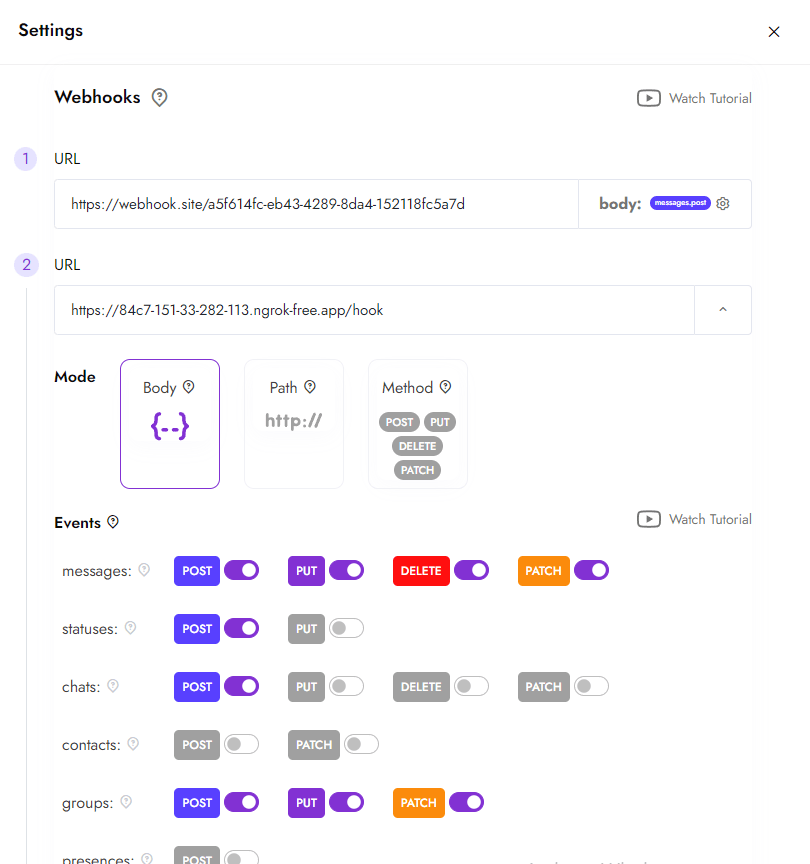
Отсканируйте QR-код, чтобы подключить номер, а затем вставьте свой публичный URL в настройки вебхука канала. Входящие сообщения приходят POST-запросами в формате JSON, как только контакт вам пишет.
В официальном WhatsApp Business API пришлось бы зарегистрировать приложение, пройти бизнес-верификацию Meta и выполнить рукопожатие проверки ещё до того, как до вашего кода дойдёт хотя бы одно сообщение. С Whapi.Cloud вы подключаете обычный номер WhatsApp, отсканировав QR-код — тем же способом, что и WhatsApp Web, — и API готов к работе примерно за две минуты. Между вами и первым входящим payload нет очереди на проверку в Meta.
Укажите в качестве URL вебхука маршрут /webhook вашего развёрнутого приложения и подпишитесь на событие messages в настройках канала. После этого Whapi.Cloud отправляет POST-запросом каждое входящее сообщение на этот маршрут. Обработчик FastAPI ниже считывает из payload номер телефона отправителя и текст сообщения.
# webhook.py -- receives inbound WhatsApp messages from Whapi.Cloud
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/webhook")
async def webhook(request: Request):
data = await request.json()
# Whapi delivers inbound messages in a "messages" array.
for msg in data.get("messages", []):
if msg.get("from_me"):
continue # skip your own outgoing messages echoed back
sender = msg["from"] # the contact's phone number, e.g. "14155551234"
text = msg.get("text", {}).get("body", "")
print(f"{sender}: {text}")
return {"status": "ok"}
Это значение sender — стержень всего агента. Оно говорит, кому отвечать, и уже через минуту станет ключом, который держит каждый разговор отдельно. Полную схему входящего сообщения смотрите в документации API Whapi.Cloud.
Соберите ReAct-агента: он выбирает инструмент, действует и смотрит на результат
ReAct-агент в LangGraph — это LLM, которая выбирает инструмент, запускает его, читает результат и повторяет, пока не сможет ответить. Сам цикл даёт LangGraph; модель и инструменты добавляете вы.
LangChain даёт обёртку для модели и абстракции инструментов. create_react_agent из LangGraph связывает их в граф с состоянием, чтобы агент мог вызвать инструмент, увидеть результат и решить, что делать дальше. Каждую возможность вы описываете обычной функцией с декоратором @tool, а затем передаёте список агенту.
# agent.py -- a tool-using ReAct agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
# Define tools as standalone functions.
# Decorating a bound method (def check_slots(self, ...)) raises a
# duplicate "self" argument error at agent-build time -- keep tools module-level.
@tool
def check_appointment_slots(day: str) -> str:
"""Return free appointment slots for a given day."""
return "09:00, 11:30, 16:00"
model = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_react_agent(
model,
tools=[check_appointment_slots],
prompt="You are a clinic's WhatsApp assistant. Keep replies short.",
)
Аргумент prompt задаёт постоянные инструкции агента и применяется заново на каждом шаге, поэтому роль ассистента остаётся прежней, даже когда разговор разрастается. Держите инструменты маленькими и с одной задачей: один читает свободные слоты для записи, другой ищет заказ, третий передаёт диалог человеку. Модель решает, что вызвать, по имени инструмента и его docstring, поэтому пишите и то, и другое как документацию к API.
Этот агент уже умеет рассуждать и вызывать инструмент. Чего он пока не умеет — это что-либо запоминать. Вызовите его дважды, и второе сообщение начнётся с чистого листа, потому что один вызов ничем не связан со следующим. На практике именно из-за этого пробела большинство первых сборок кажутся сломанными.
Приравняйте thread_id к номеру телефона — и у каждого пользователя будет своя память
Подключите checkpointer и в каждом вызове передавайте thread_id, равный номеру телефона отправителя. Одна эта строка отделяет общий на всех «мозг» от отдельной памяти для каждого контакта.
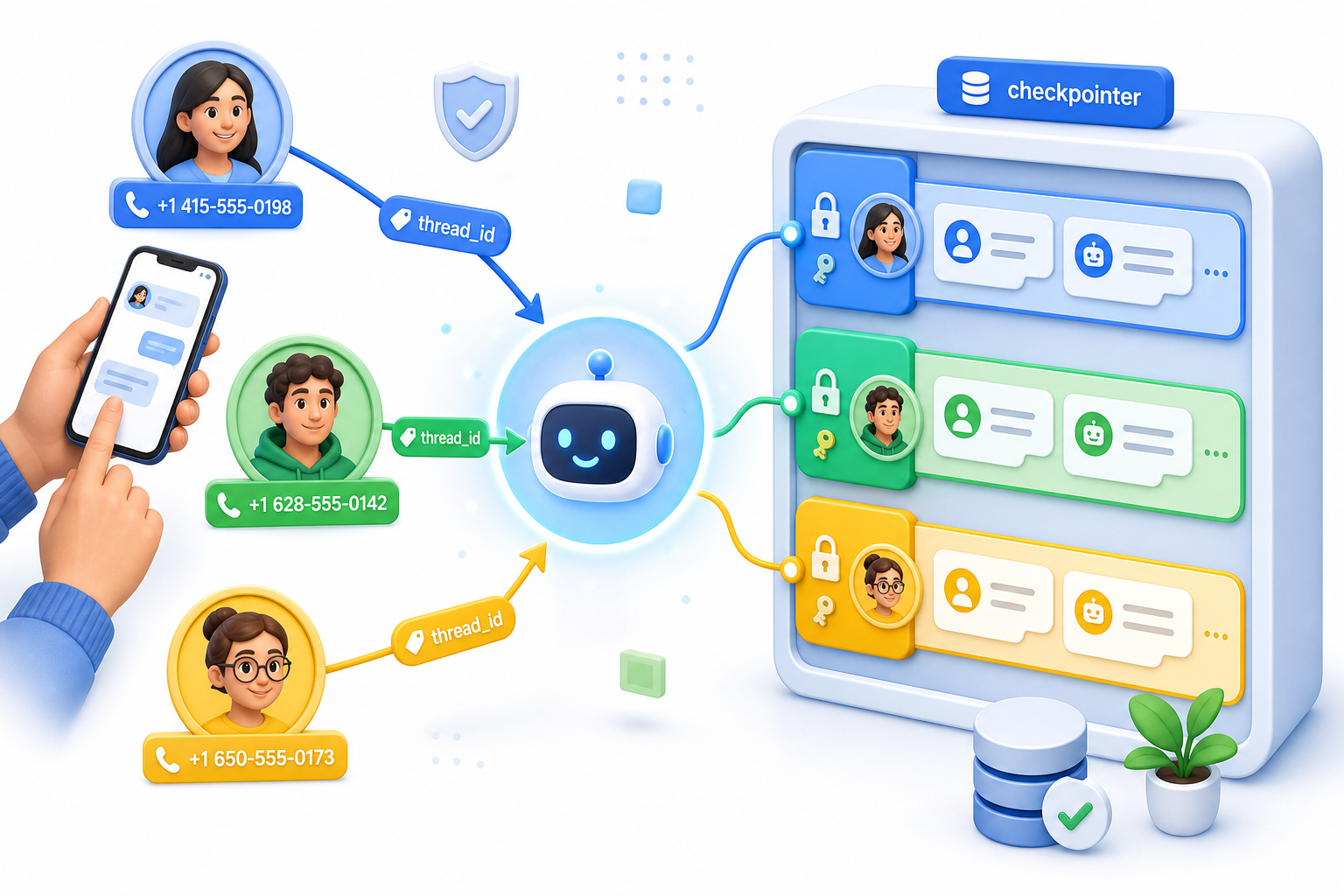
Без checkpointer все пользователи делят одно состояние разговора, поэтому второй написавший наследует контекст первого. С checkpointer и отдельным thread_id для каждого пользователя у каждого контакта появляется свой изолированный поток. Возьмите номер телефона из вебхука в качестве этого thread_id — и маршрутизация решится сама собой. Мы называем это правилом «номер вместо thread_id», и на нём держится вся сборка.
# memory.py -- one isolated conversation per phone number
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = MemorySaver() # in-memory; resets on restart
# For production, swap one line:
# from langgraph.checkpoint.postgres import PostgresSaver
# checkpointer = PostgresSaver.from_conn_string("postgresql://...")
agent = create_react_agent(model, tools=tools, checkpointer=checkpointer)
def reply_for(sender: str, text: str) -> str:
# thread_id = phone number -> each contact keeps a separate conversation
config = {"configurable": {"thread_id": sender}}
result = agent.invoke({"messages": [("user", text)]}, config=config)
return result["messages"][-1].content
MemorySaver хранит каждый поток в памяти и идеально подходит для прототипа. При перезапуске он всё забывает — и это не проблема, пока дело не дошло до деплоя. Правило «номер вместо thread_id» не меняется при переходе в продакшен; меняется только хранилище за checkpointer. Открытые WhatsApp-агенты, которые работают в продакшене, используют ровно этот подход с привязкой к номеру телефона.
Почему связка «ngrok плюс Business API» ломается первой
Привычный путь из туториалов тянет за собой локальный туннель, шаблоны сообщений и 24-часовое окно для ответа ещё до того, как заработает хоть какая-то логика ИИ. Путь с одним вебхуком обходит все три.
Скорее всего, сначала вы возьмёте стандартную схему: туннель ngrok, чтобы Meta могла достучаться до вашего ноутбука, плюс официальный Business API для отправки. И вот где именно она ломается. URL туннеля меняется при каждом перезапуске и обрывается без предупреждения, поэтому вебхук тихо перестаёт принимать сообщения, хотя код выглядит исправным. А дальше своё трение добавляет сторона отправки.
В официальном WhatsApp Business API любое сообщение, которое вы начинаете вне 24-часового окна, должно быть заранее одобренным шаблоном, и примерно один шаблон из трёх отклоняют при первой проверке из-за формата или категории. С 1 июля 2025 года Meta вдобавок берёт плату за каждое доставленное шаблонное сообщение по тарифу, зависящему от категории и страны, — модель с целым рядом скрытых расходов для разработчиков. С Whapi.Cloud агент отвечает обычным текстом через один вызов API, поэтому нет ни очереди на одобрение шаблонов, ни поштучной оплаты, за которой нужно следить. Вот и весь аргумент о предсказуемости расходов в одной фразе: ответ, который можно отправить свободно, нельзя ни отклонить, ни обложить доплатой.
| Что нужно для сборки | Один вебхук Whapi.Cloud | ngrok + официальный Business API |
|---|---|---|
| Приём сообщений локально | Размещённый URL вебхука, без туннеля | Туннель ngrok: меняет URL и обрывается |
| Настройка аккаунта | Скан QR-кода, готово за ~2 минуты | Бизнес-верификация Meta: от дней до недель |
| Отправка ответа | Свободный текст, один REST-запрос | Заранее одобренный шаблон, ~1 из 3 отклоняют |
| Сроки ответа | Нет 24-часового сервисного окна | Свободный текст только внутри 24-часового окна |
| Модель оплаты отправки | Подписка, без платы за шаблон по сообщениям | Оплата за доставленный шаблон с июля 2025 |
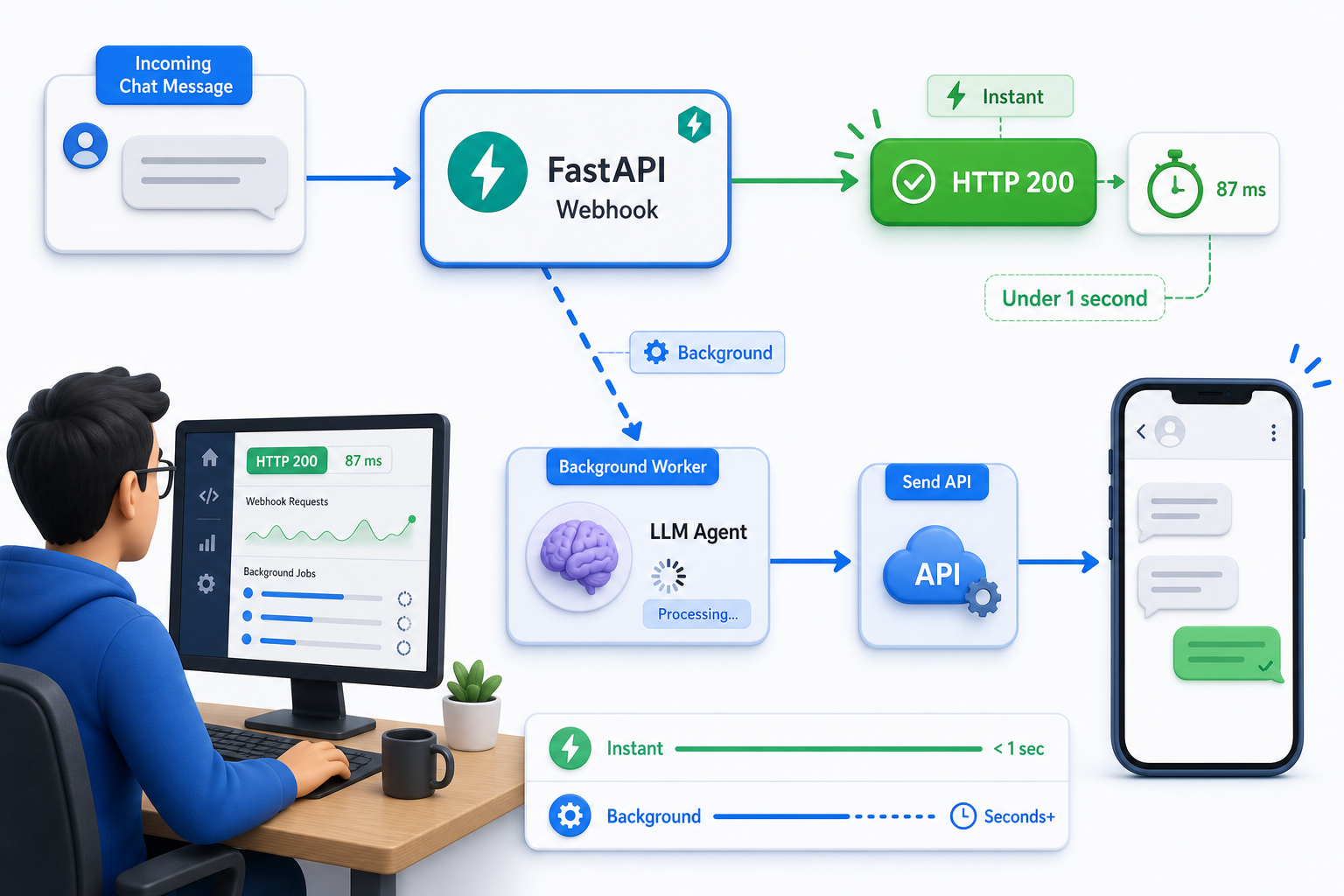
Быстро верните 200, а агента запускайте в фоне
Сразу подтвердите вебхук статусом HTTP 200, а медленный вызов LLM запускайте в фоновой задаче. Медленный ответ ни в коем случае не должен держать соединение вебхука открытым.
Подпишитесь только на событие messages в настройках канала, чтобы маршрут не будили статусы доставки и отметки о прочтении. Каждый входящий payload вебхука несёт номер отправителя, тип сообщения и текст; пропускайте всё, где from_me равно true, чтобы бот не отвечал на собственные сообщения.
Вызов LLM занимает несколько секунд, а подтверждение вебхука должно укладываться в миллисекунды. Если обработчик ждёт агента перед ответом, доставка может выйти за таймаут, и то же сообщение придёт повторно — пользователь получит ответ дважды. BackgroundTasks в FastAPI позволяет ответить сразу, а обработать потом.
# webhook_async.py -- fast 200, then reason and reply in the background
import os, requests
from fastapi import FastAPI, Request, BackgroundTasks
app = FastAPI()
def handle(sender: str, text: str):
answer = reply_for(sender, text) # the slow part: agent + LLM
# POST https://gate.whapi.cloud/messages/text
# If you block the webhook waiting for this, Whapi retries the
# delivery and the contact gets the same answer twice.
requests.post(
"https://gate.whapi.cloud/messages/text",
headers={"Authorization": f"Bearer {os.environ['WHAPI_TOKEN']}"},
json={"to": sender, "body": answer},
timeout=30,
)
@app.post("/webhook")
async def webhook(request: Request, background: BackgroundTasks):
data = await request.json()
for msg in data.get("messages", []):
if msg.get("from_me"):
continue
background.add_task(handle, msg["from"], msg.get("text", {}).get("body", ""))
return {"status": "ok"} # returned in milliseconds
Ответ уходит обратно через POST /messages/text: номер отправителя — в поле to, ответ агента — в body. Поскольку маршрут отвечает раньше, чем агент закончит, доставка остаётся быстрой, а баги с двойным ответом исчезают. Чаще всего в сломанных первых сборках мы видим синхронный обработчик, который зависает на модели и незаметно приучает шлюз к повторам.
От прототипа к продакшену: замените MemorySaver на Postgres
MemorySaver помнит до следующего перезапуска, а checkpointer на Postgres — переживает деплои и сбои. Замена в одну строку, потому что правило «номер вместо thread_id» остаётся тем же.
Разверните приложение FastAPI на любом публичном хосте, чтобы URL вебхука был доступен, задайте WHAPI_TOKEN и ключ модели через переменные окружения и замените MemorySaver на PostgresSaver. После этого состояние разговора переживает перезапуски, а те же потоки по пользователям продолжают работать без единого изменения в коде самого агента.
Типичные ошибки при первой сборке (и как их исправить)
На двух ошибках спотыкается почти каждая первая сборка: не та обёртка OpenAI и инструмент, объявленный методом класса. Обе падают ещё при запуске с непонятными сообщениями.
Если передать имя чат-модели вроде gpt-4o в старую обёртку для completions, OpenAI вернёт This is a chat model and not supported in the v1/completions endpoint. Решение — использовать ChatOpenAI, а не класс OpenAI в стиле completion.
# Wrong: completion wrapper rejects chat models
# from langchain_openai import OpenAI
# model = OpenAI(model="gpt-4o") # -> v1/completions endpoint error
# Right: chat model wrapper
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
Вторая ошибка появляется, когда вы вешаете @tool на метод экземпляра. LangChain читает self как обязательный аргумент инструмента, и сборка агента падает. Объявляйте инструменты функциями на уровне модуля, а общее состояние передавайте через замыкание или глобальный клиент.
Если непонятное поведение возникает на стороне WhatsApp, а не в вашем Python, напишите команде поддержки Whapi.Cloud через чат на whapi.cloud — команда активно помогает клиентам решать проблемы в продакшене. Расшифровку голосовых и поиск по векторам мы здесь не разбираем: и то, и другое надстраивается над этим же циклом и заслуживает отдельного руководства.
Вот и вся сборка: один вебхук Whapi.Cloud принимает, агент LangGraph рассуждает с памятью по номеру телефона каждого собеседника, а один REST-запрос отправляет ответ. Коротким всё это остаётся именно потому, что мы пропустили туннели, верификацию в Meta и одобрение шаблонов. Команды, которые автоматизируют запись на этом цикле, отмечают, что число неявок падает на четверть и больше, — поэтому память для каждого пользователя стоит настроить правильно. Свяжите три шага, как показано, и агент будет вести настоящий разговор от сообщения к сообщению.