TL;DR: Execute o ciclo de receber, raciocinar e responder em um único webhook da Whapi.Cloud. Defina o thread_id do LangGraph como o número de telefone do remetente com um checkpointer, para que cada contato mantenha sua própria memória. Retorne um HTTP 200 em menos de um segundo e rode o agente em uma tarefa em segundo plano. Sem ngrok, sem verificação da Meta e sem modelos de mensagem. Comece com o MemorySaver e troque por um checkpointer no Postgres para produção.
O ciclo de três etapas que todo agente de WhatsApp executa
Um agente de IA para WhatsApp é um único ciclo: receber a mensagem, raciocinar com um agente que usa ferramentas e enviar a resposta. Todo o resto é a fiação em torno dessas três etapas.
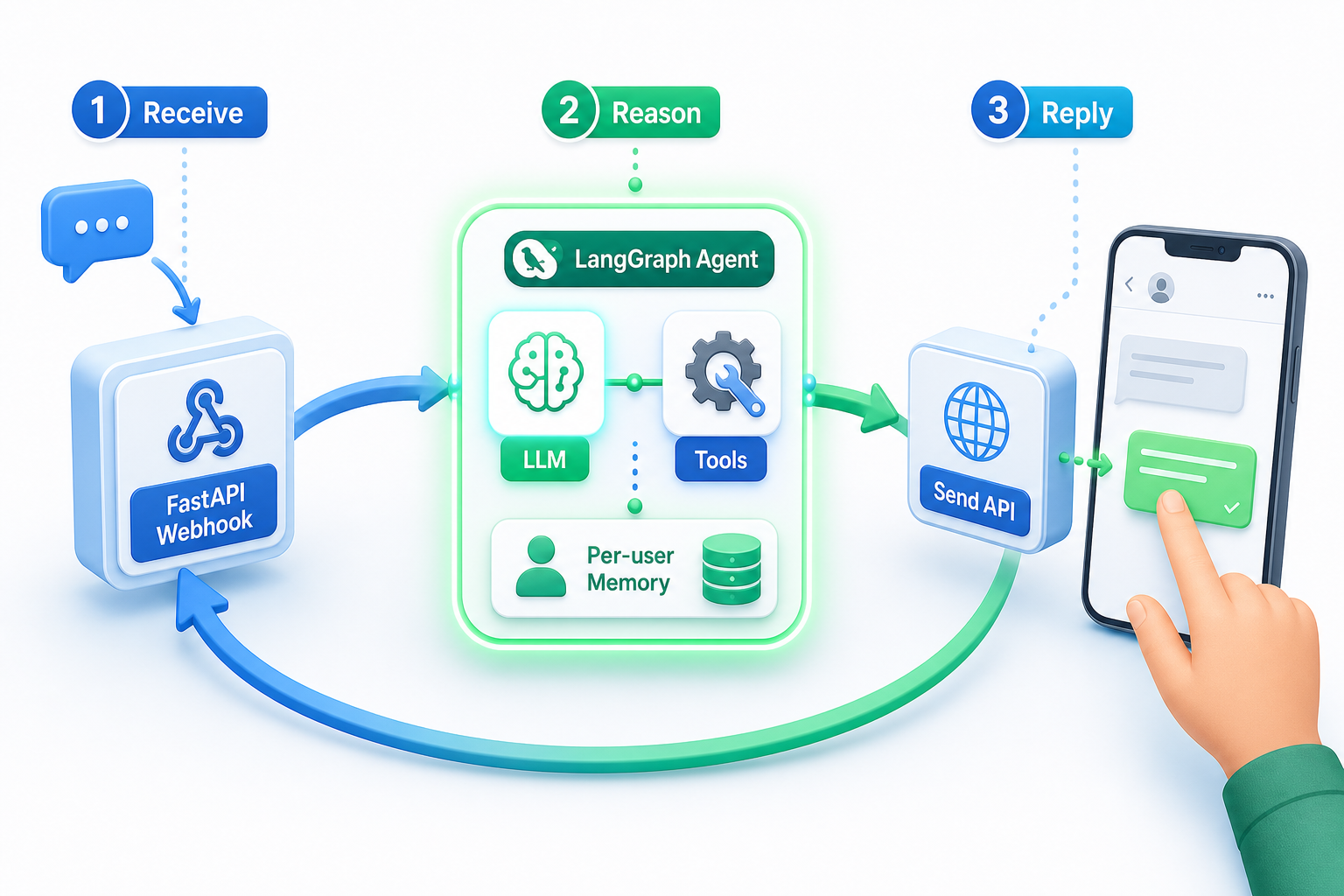
Nesta montagem, uma rota do FastAPI recebe a mensagem recebida da Whapi.Cloud, um agente do LangGraph movido pelo ChatOpenAI decide o que fazer e uma única chamada REST envia a resposta de volta. O número de telefone que mandou mensagem para você é o único identificador que você precisa carregar pelas três etapas.
Conecte o número e aponte um webhook para o seu app
Escaneie um QR code para conectar o número e depois cole sua URL pública nas configurações de webhook do canal. As mensagens recebidas chegam como POSTs em JSON no momento em que um contato escreve para você.
Na API oficial do WhatsApp Business, você teria que registrar um app, passar pela verificação de empresa da Meta e executar um handshake de verificação antes que uma única mensagem chegasse ao seu código. Com a Whapi.Cloud, você conecta um número de WhatsApp comum escaneando um QR code, o mesmo pareamento que o WhatsApp Web usa, e a API fica ativa em cerca de dois minutos. Não há fila de revisão da Meta entre você e o seu primeiro payload recebido.
Defina a URL do webhook com a rota /webhook do seu app já publicado e inscreva-se no evento messages nas configurações do canal. A Whapi.Cloud então envia por POST cada mensagem recebida para essa rota. O handler do FastAPI abaixo lê o número de telefone do remetente e o corpo do texto do payload.
# webhook.py -- receives inbound WhatsApp messages from Whapi.Cloud
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/webhook")
async def webhook(request: Request):
data = await request.json()
# Whapi delivers inbound messages in a "messages" array.
for msg in data.get("messages", []):
if msg.get("from_me"):
continue # skip your own outgoing messages echoed back
sender = msg["from"] # the contact's phone number, e.g. "14155551234"
text = msg.get("text", {}).get("body", "")
print(f"{sender}: {text}")
return {"status": "ok"}
Esse valor sender é a espinha dorsal de todo o agente. Ele diz a quem responder e, em um instante, vira a chave que mantém cada conversa separada. Consulte a documentação da API da Whapi.Cloud para ver o esquema completo da mensagem recebida.
Crie o agente ReAct que escolhe ferramentas, age e depois observa
Um agente ReAct do LangGraph é um LLM que escolhe uma ferramenta, executa, lê o resultado e repete até conseguir responder. O LangGraph fornece o ciclo; você fornece o modelo e as ferramentas.
O LangChain dá a você o wrapper do modelo e as abstrações de ferramentas. O create_react_agent do LangGraph conecta tudo em um grafo com estado para que o agente possa chamar uma ferramenta, observar a saída e decidir o próximo passo. Você define cada capacidade como uma função simples decorada com @tool e depois entrega a lista ao agente.
# agent.py -- a tool-using ReAct agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
# Define tools as standalone functions.
# Decorating a bound method (def check_slots(self, ...)) raises a
# duplicate "self" argument error at agent-build time -- keep tools module-level.
@tool
def check_appointment_slots(day: str) -> str:
"""Return free appointment slots for a given day."""
return "09:00, 11:30, 16:00"
model = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_react_agent(
model,
tools=[check_appointment_slots],
prompt="You are a clinic's WhatsApp assistant. Keep replies short.",
)
O argumento prompt define as instruções permanentes do agente e é reaplicado a cada turno, de modo que o papel do assistente permanece estável mesmo quando a conversa cresce. Mantenha as ferramentas pequenas e com um único propósito: uma para ler horários de consulta, outra para consultar um pedido e outra para escalar para um humano. O modelo decide qual chamar pelo nome da ferramenta e pela docstring, então escreva os dois como se fossem a documentação de uma API.
Esse agente já consegue raciocinar e chamar uma ferramenta. O que ele ainda não consegue fazer é lembrar de nada. Invoque-o duas vezes e a segunda mensagem começa do zero, porque nada liga uma chamada à seguinte. Na prática, é nessa lacuna que a maioria das primeiras montagens parece quebrada.
Defina o thread_id como o número de telefone e cada usuário mantém a própria memória
Conecte um checkpointer e passe um thread_id igual ao número de telefone do remetente em cada chamada. Essa única linha é a diferença entre um cérebro compartilhado e uma memória por contato.
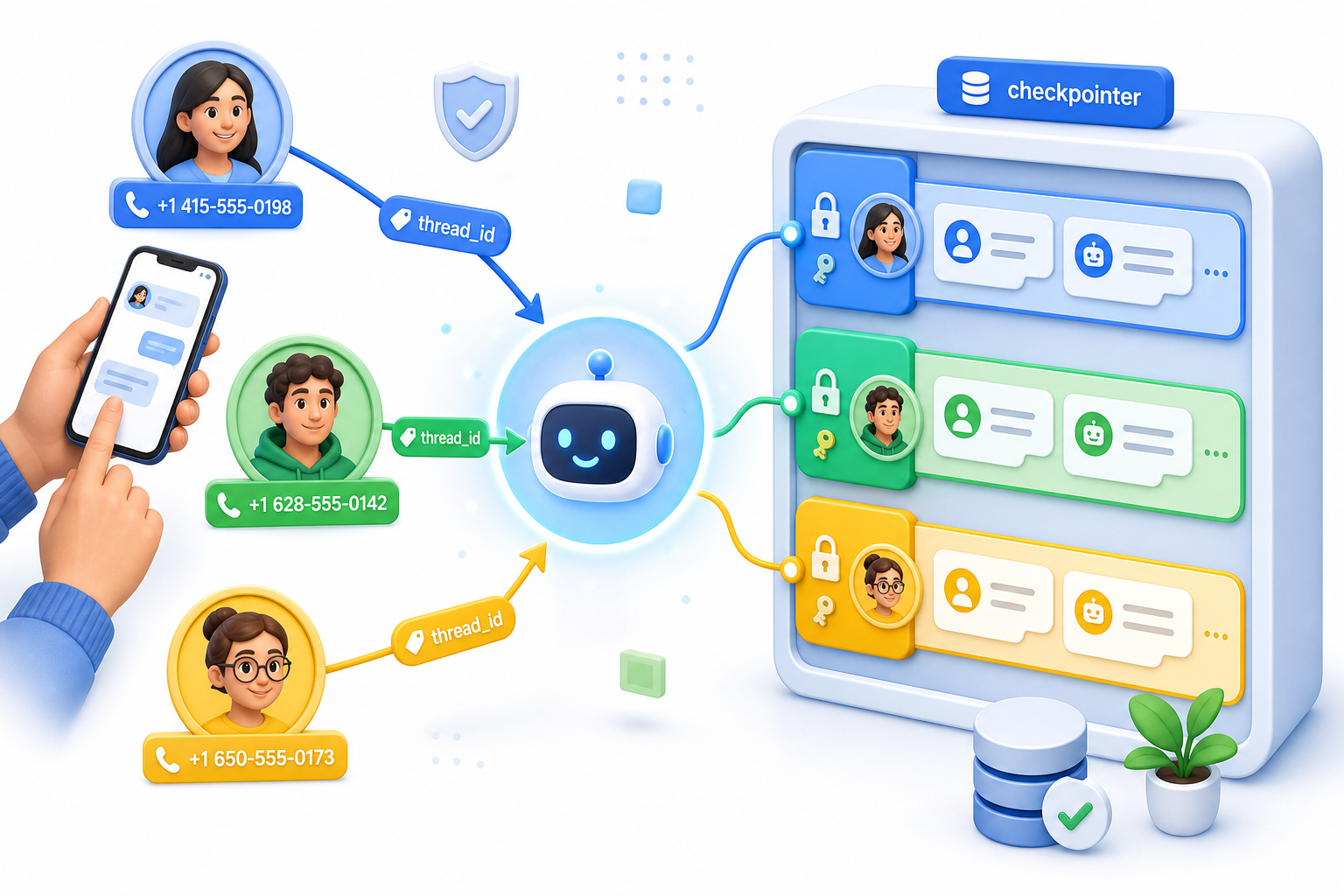
Sem um checkpointer, todos os usuários compartilham um mesmo estado de conversa, então a segunda pessoa a mandar mensagem herda o contexto da primeira. Com um checkpointer mais um thread_id por usuário, cada contato ganha um thread isolado. Use o número de telefone do webhook como esse thread_id e o roteamento se resolve sozinho. Chamamos isso de regra do telefone como thread_id, e é a decisão que sustenta toda a montagem.
# memory.py -- one isolated conversation per phone number
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = MemorySaver() # in-memory; resets on restart
# For production, swap one line:
# from langgraph.checkpoint.postgres import PostgresSaver
# checkpointer = PostgresSaver.from_conn_string("postgresql://...")
agent = create_react_agent(model, tools=tools, checkpointer=checkpointer)
def reply_for(sender: str, text: str) -> str:
# thread_id = phone number -> each contact keeps a separate conversation
config = {"configurable": {"thread_id": sender}}
result = agent.invoke({"messages": [("user", text)]}, config=config)
return result["messages"][-1].content
O MemorySaver mantém cada thread na memória e é perfeito para o protótipo. Ele esquece tudo ao reiniciar, o que não é problema até a hora de publicar. A regra do telefone como thread_id não muda quando você vai para produção; só muda o armazenamento por trás do checkpointer. Agentes de WhatsApp de código aberto rodando em produção usam exatamente esse padrão, indexado pelo número de telefone.
Por que «usar o ngrok e a Business API» quebra primeiro
O caminho comum dos tutoriais arrasta um túnel local, modelos de mensagem e uma janela de resposta de 24 horas antes de qualquer lógica de IA rodar. O caminho de um único webhook pula os três.
É provável que você primeiro recorra à configuração padrão: um túnel ngrok para que a Meta alcance o seu notebook, mais a Business API oficial para enviar. É exatamente aqui que ela quebra. A URL do túnel muda a cada reinício e cai sem aviso, então o seu webhook para de receber em silêncio enquanto o seu código parece estar certo. E aí o lado do envio adiciona o seu próprio atrito.
Na API oficial do WhatsApp Business, qualquer mensagem que você inicie fora de uma janela de 24 horas precisa ser um modelo aprovado previamente, e cerca de um em cada três modelos é rejeitado na primeira revisão por questões de formato ou de categoria. Desde 1º de julho de 2025, a Meta também cobra por modelo de mensagem entregue, com preço por categoria e país, um modelo com vários custos ocultos para desenvolvedores. Com a Whapi.Cloud, o agente responde com um texto livre por meio de uma única chamada de API, então não há fila de aprovação de modelos nem cobrança por modelo para fiscalizar. Esse é o argumento da previsibilidade de custos em uma frase: uma resposta que você pode enviar livremente não pode ser rejeitada nem sobretaxada.
| O que a montagem precisa | Um único webhook da Whapi.Cloud | ngrok + Business API oficial |
|---|---|---|
| Receber mensagens localmente | URL de webhook hospedada, sem túnel | Túnel ngrok que troca as URLs e cai |
| Configuração da conta | Leitura de QR code, ativo em ~2 minutos | Verificação de empresa da Meta, de dias a semanas |
| Enviar uma resposta | Texto livre, uma chamada REST | Modelo aprovado previamente, ~1 em cada 3 rejeitado |
| Prazo de resposta | Sem janela de atendimento de 24 horas | Texto livre só dentro de uma janela de 24 horas |
| Modelo de custo de envio | Assinatura, sem taxa de modelo por mensagem | Cobrança por modelo entregue desde julho de 2025 |
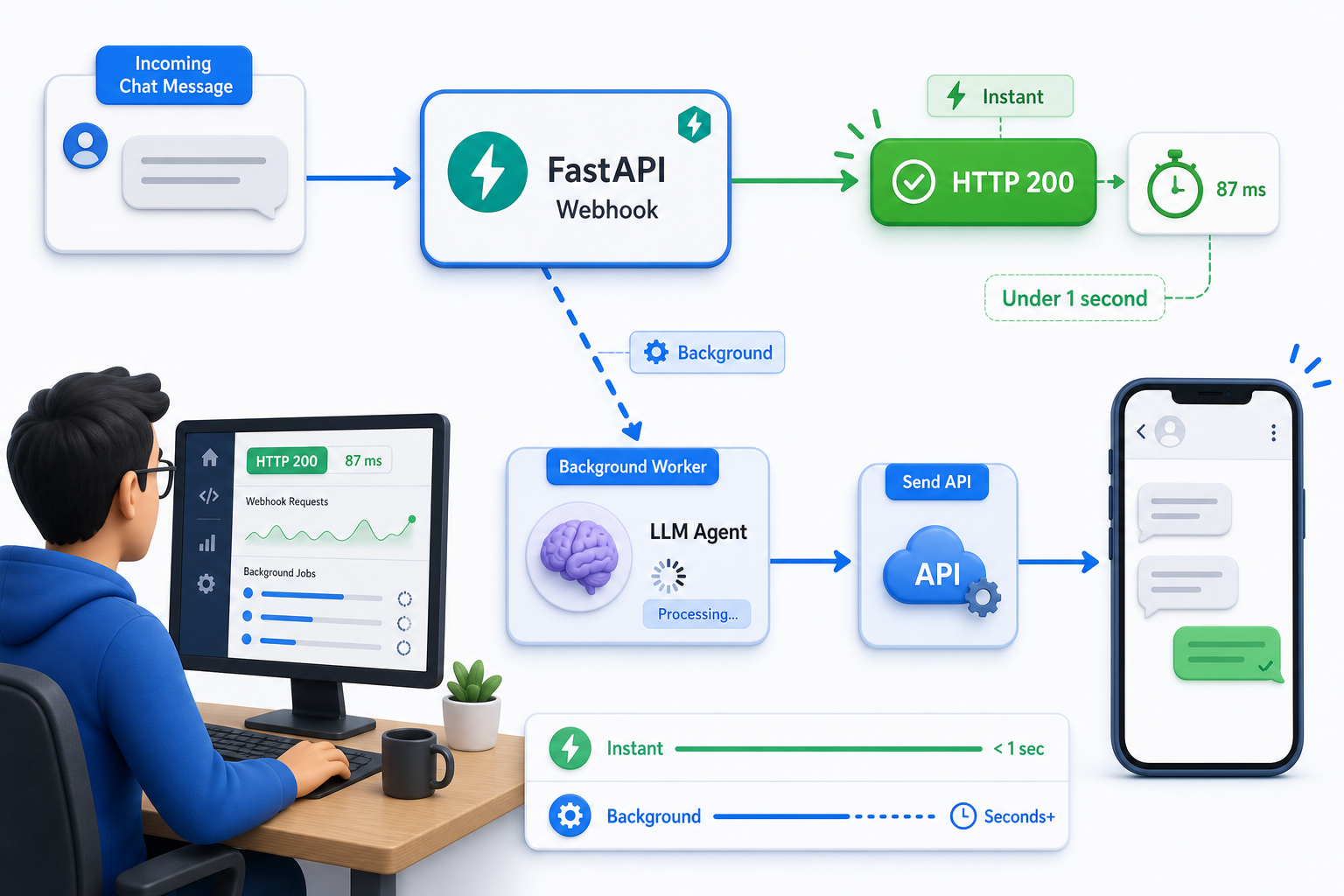
Retorne 200 rápido e rode o agente em segundo plano
Confirme o webhook com um HTTP 200 imediatamente e depois rode a lenta chamada ao LLM em uma tarefa em segundo plano. Uma resposta lenta nunca deve manter a conexão do webhook aberta.
Inscreva-se apenas no evento messages nas configurações do canal para que a sua rota não seja acordada por atualizações de status e confirmações de leitura. Cada payload de webhook recebido traz o número do remetente, o tipo da mensagem e o corpo do texto; ignore tudo em que from_me for verdadeiro para que o bot não responda às próprias mensagens.
Uma chamada ao LLM leva alguns segundos; a confirmação de um webhook deveria levar milissegundos. Se o seu handler espera o agente antes de retornar, a entrega pode estourar o tempo e a mesma mensagem é entregue de novo, então o usuário recebe a resposta duas vezes. O BackgroundTasks do FastAPI deixa você retornar na hora e processar depois.
# webhook_async.py -- fast 200, then reason and reply in the background
import os, requests
from fastapi import FastAPI, Request, BackgroundTasks
app = FastAPI()
def handle(sender: str, text: str):
answer = reply_for(sender, text) # the slow part: agent + LLM
# POST https://gate.whapi.cloud/messages/text
# If you block the webhook waiting for this, Whapi retries the
# delivery and the contact gets the same answer twice.
requests.post(
"https://gate.whapi.cloud/messages/text",
headers={"Authorization": f"Bearer {os.environ['WHAPI_TOKEN']}"},
json={"to": sender, "body": answer},
timeout=30,
)
@app.post("/webhook")
async def webhook(request: Request, background: BackgroundTasks):
data = await request.json()
for msg in data.get("messages", []):
if msg.get("from_me"):
continue
background.add_task(handle, msg["from"], msg.get("text", {}).get("body", ""))
return {"status": "ok"} # returned in milliseconds
A resposta volta por POST /messages/text com o número do remetente no campo to e a resposta do agente em body. Como a rota retorna antes de o agente terminar, as entregas continuam rápidas e os bugs de resposta duplicada somem. O padrão que mais encontramos em primeiras montagens quebradas é um handler síncrono que trava no modelo e, sem querer, ensina o gateway a tentar de novo.
Do protótipo à produção: troque o MemorySaver pelo Postgres
O MemorySaver lembra até o próximo reinício; um checkpointer no Postgres lembra entre publicações e quedas. A troca é de uma linha porque a regra do telefone como thread_id continua idêntica.
Publique o app FastAPI em qualquer host público para que a URL do webhook seja acessível, defina WHAPI_TOKEN e a chave do seu modelo como variáveis de ambiente e substitua o MemorySaver pelo PostgresSaver. O estado da conversa passa a sobreviver a reinícios, e os mesmos threads por usuário continuam funcionando sem nenhuma mudança no código do próprio agente.
Erros comuns de quem monta pela primeira vez (e a solução)
Dois erros derrubam quase toda primeira montagem: o wrapper errado da OpenAI e uma ferramenta definida como método de classe. Os dois falham na inicialização com mensagens confusas.
Se você passar o nome de um modelo de chat como gpt-4o para o antigo wrapper de completion, a OpenAI retorna This is a chat model and not supported in the v1/completions endpoint. A correção é usar ChatOpenAI, não a classe OpenAI no estilo completion.
# Wrong: completion wrapper rejects chat models
# from langchain_openai import OpenAI
# model = OpenAI(model="gpt-4o") # -> v1/completions endpoint error
# Right: chat model wrapper
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
O segundo erro aparece quando você decora um método de instância com @tool. O LangChain lê self como um argumento obrigatório da ferramenta e a construção do agente falha. Defina as ferramentas como funções no nível do módulo e passe qualquer estado compartilhado por um closure ou por um cliente global.
Se você esbarrar em um comportamento inesperado no lado do WhatsApp, e não no seu Python, fale com a equipe de suporte da Whapi.Cloud pelo chat em whapi.cloud: a equipe ajuda ativamente os clientes a resolver problemas em produção. Não vamos cobrir aqui a transcrição de notas de voz nem a busca por vetores; ambas ficam em cima desse mesmo ciclo e merecem um guia próprio.
É essa a montagem inteira: um webhook da Whapi.Cloud recebe, um agente do LangGraph raciocina com memória indexada pelo número de telefone de cada pessoa e uma única chamada REST envia a resposta. Pular túneis, a verificação da Meta e a aprovação de modelos é o que a mantém tão curta. Equipes que automatizam o agendamento de consultas nesse ciclo relatam quedas de um quarto ou mais nas ausências, e é por isso que vale a pena acertar o padrão de memória por usuário. Conecte as três etapas como mostrado e o agente mantém uma conversa de verdade ao longo das mensagens.