TL;DR: Ejecuta el ciclo de recibir, razonar y responder en un solo webhook de Whapi.Cloud. Asigna el thread_id de LangGraph al número de teléfono del remitente con un checkpointer, para que cada contacto conserve su propia memoria. Devuelve un HTTP 200 en menos de un segundo y ejecuta el agente en una tarea en segundo plano. Sin ngrok, sin verificación de Meta y sin plantillas de mensajes. Empieza con MemorySaver y cambia a un checkpointer de Postgres para producción.
El ciclo de tres pasos que ejecuta todo agente de WhatsApp
Un agente de IA para WhatsApp es un solo ciclo: recibir el mensaje, razonar con un agente que usa herramientas y enviar la respuesta. Todo lo demás son conexiones alrededor de esos tres pasos.
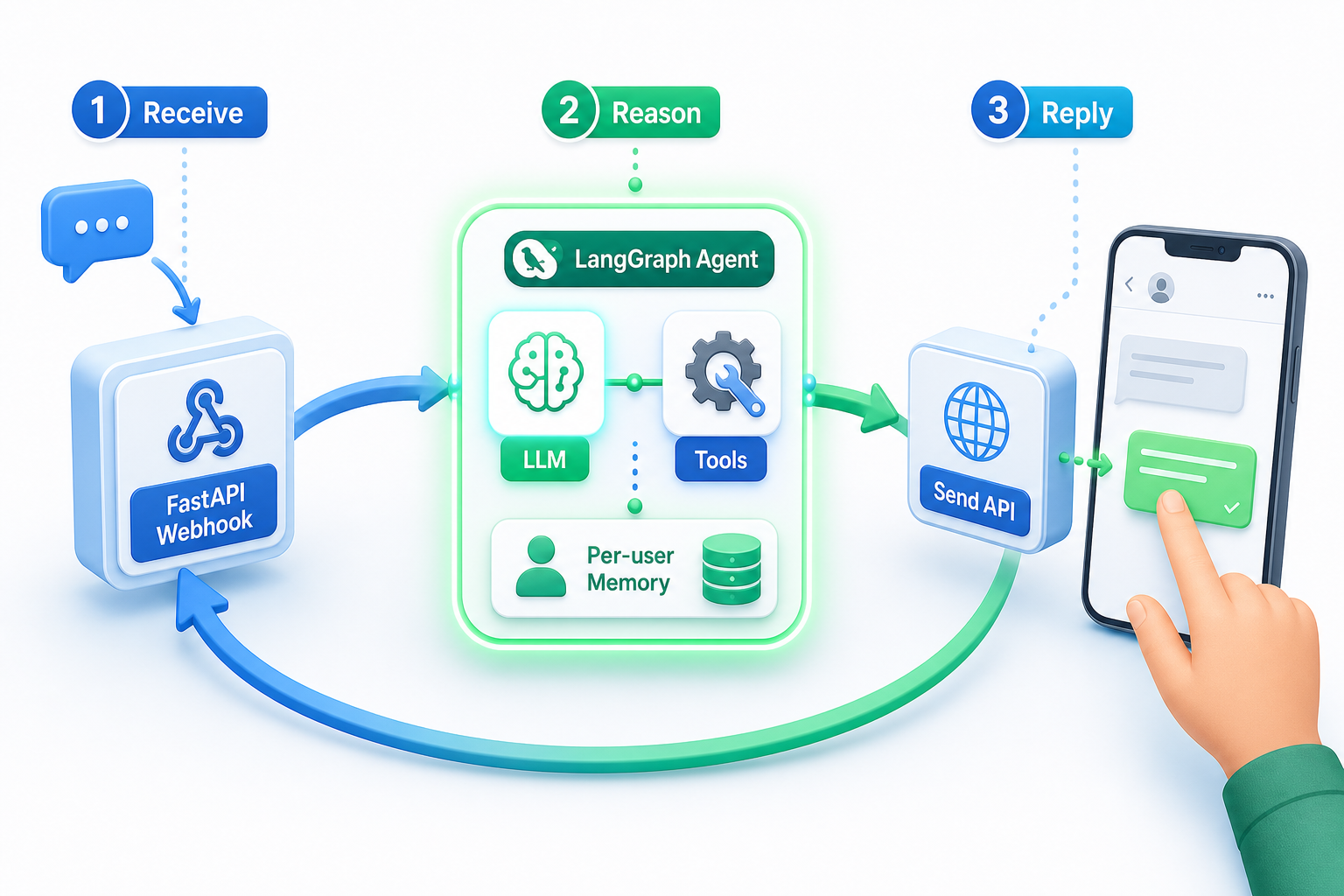
En esta implementación, una ruta de FastAPI recibe el mensaje entrante de Whapi.Cloud, un agente de LangGraph impulsado por ChatOpenAI decide qué hacer y una sola llamada REST envía la respuesta de vuelta. El número de teléfono que te escribió es el único identificador que necesitas arrastrar por los tres pasos.
Conecta el número y apunta un webhook a tu aplicación
Escanea un código QR para conectar el número y luego pega tu URL pública en la configuración de webhook del canal. Los mensajes entrantes llegan como POST en JSON en cuanto un contacto te escribe.
Con la API oficial de WhatsApp Business tendrías que registrar una app, pasar la verificación de empresa de Meta y completar un intercambio de verificación antes de que un solo mensaje llegue a tu código. Con Whapi.Cloud conectas un número de WhatsApp normal escaneando un código QR, el mismo emparejamiento que usa WhatsApp Web, y la API queda activa en unos dos minutos. No hay cola de revisión de Meta entre tú y tu primer payload entrante.
Configura la URL del webhook con la ruta /webhook de tu aplicación desplegada y suscríbete al evento messages en la configuración del canal. Whapi.Cloud enviará entonces por POST cada mensaje entrante a esa ruta. El manejador de FastAPI que aparece abajo lee el número de teléfono del remitente y el cuerpo del texto del payload.
# webhook.py -- receives inbound WhatsApp messages from Whapi.Cloud
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/webhook")
async def webhook(request: Request):
data = await request.json()
# Whapi delivers inbound messages in a "messages" array.
for msg in data.get("messages", []):
if msg.get("from_me"):
continue # skip your own outgoing messages echoed back
sender = msg["from"] # the contact's phone number, e.g. "14155551234"
text = msg.get("text", {}).get("body", "")
print(f"{sender}: {text}")
return {"status": "ok"}
Ese valor sender es la columna vertebral de todo el agente. Te dice a quién responder y, en un momento, se convierte en la clave que mantiene separada cada conversación. Consulta la documentación de la API de Whapi.Cloud para ver el esquema completo del mensaje entrante.
Crea el agente ReAct que elige herramientas, actúa y luego observa
Un agente ReAct de LangGraph es un LLM que elige una herramienta, la ejecuta, lee el resultado y repite hasta poder responder. LangGraph aporta el ciclo; tú aportas el modelo y las herramientas.
LangChain te da el envoltorio del modelo y las abstracciones de herramientas. El create_react_agent de LangGraph las conecta en un grafo con estado para que el agente pueda llamar a una herramienta, observar el resultado y decidir su siguiente paso. Defines cada capacidad como una función normal decorada con @tool y luego le pasas la lista al agente.
# agent.py -- a tool-using ReAct agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
# Define tools as standalone functions.
# Decorating a bound method (def check_slots(self, ...)) raises a
# duplicate "self" argument error at agent-build time -- keep tools module-level.
@tool
def check_appointment_slots(day: str) -> str:
"""Return free appointment slots for a given day."""
return "09:00, 11:30, 16:00"
model = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_react_agent(
model,
tools=[check_appointment_slots],
prompt="You are a clinic's WhatsApp assistant. Keep replies short.",
)
El argumento prompt fija las instrucciones permanentes del agente y se vuelve a aplicar en cada turno, de modo que el rol del asistente se mantiene estable aunque la conversación crezca. Mantén las herramientas pequeñas y con un solo propósito: una para leer huecos de citas, otra para consultar un pedido y otra para escalar a una persona. El modelo decide cuál llamar a partir del nombre de la herramienta y su docstring, así que escribe ambos como si fueran documentación de una API.
Este agente ya puede razonar y llamar a una herramienta. Lo que todavía no puede hacer es recordar nada. Invócalo dos veces y el segundo mensaje empieza de cero, porque nada conecta una llamada con la siguiente. En la práctica, ese vacío es donde la mayoría de las primeras implementaciones parecen estar rotas.
Asigna thread_id al número de teléfono y cada usuario conserva su propia memoria
Conecta un checkpointer y pasa un thread_id igual al número de teléfono del remitente en cada llamada. Esa única línea es la diferencia entre un cerebro compartido y una memoria por cada contacto.
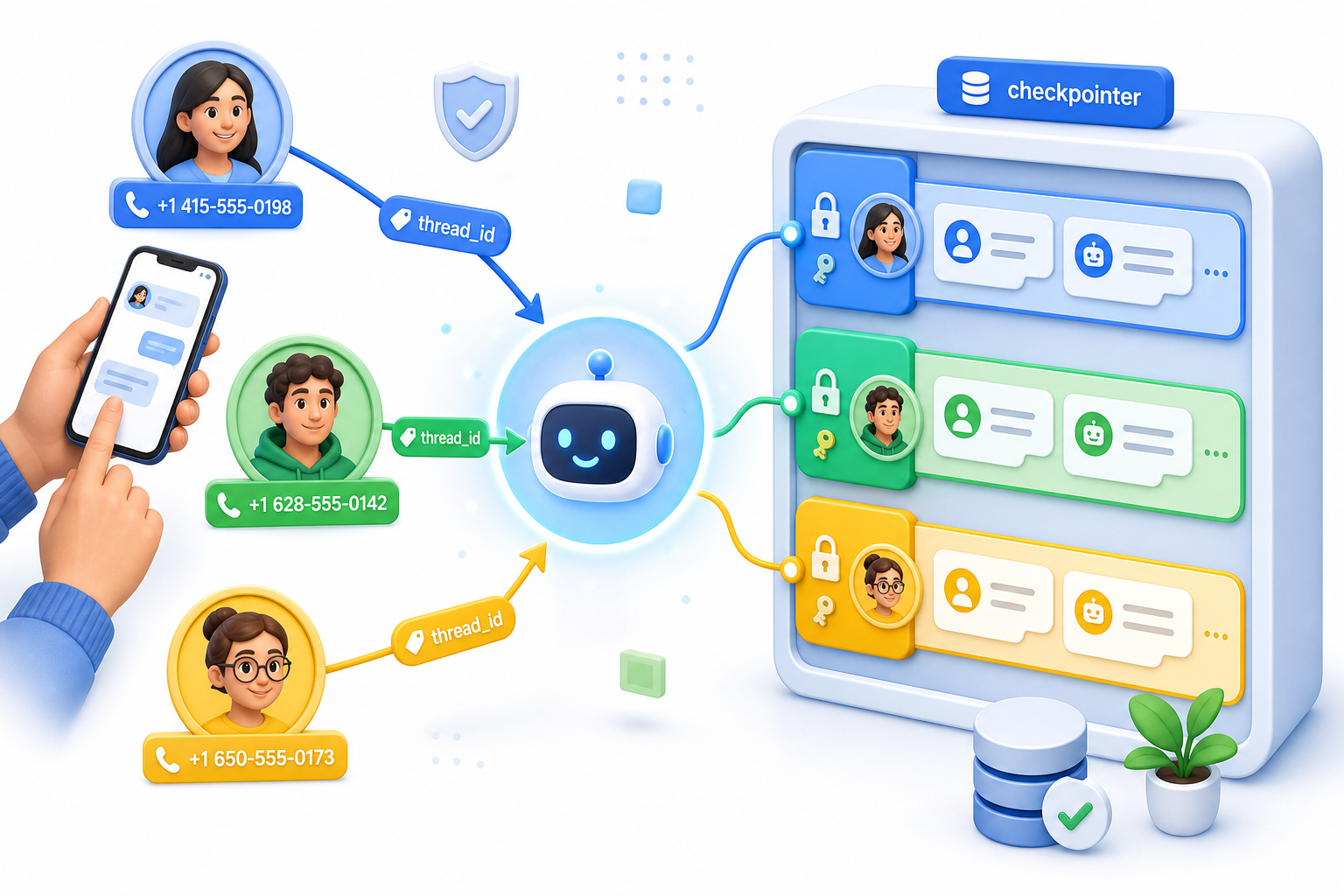
Sin un checkpointer, todos los usuarios comparten un mismo estado de conversación, así que la segunda persona que escribe hereda el contexto de la primera. Con un checkpointer más un thread_id por usuario, cada contacto obtiene un hilo aislado. Usa el número de teléfono del webhook como ese thread_id y el enrutamiento se resuelve solo. A esto lo llamamos la regla del teléfono como thread_id, y es la decisión que sostiene toda la implementación.
# memory.py -- one isolated conversation per phone number
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = MemorySaver() # in-memory; resets on restart
# For production, swap one line:
# from langgraph.checkpoint.postgres import PostgresSaver
# checkpointer = PostgresSaver.from_conn_string("postgresql://...")
agent = create_react_agent(model, tools=tools, checkpointer=checkpointer)
def reply_for(sender: str, text: str) -> str:
# thread_id = phone number -> each contact keeps a separate conversation
config = {"configurable": {"thread_id": sender}}
result = agent.invoke({"messages": [("user", text)]}, config=config)
return result["messages"][-1].content
MemorySaver mantiene cada hilo en memoria y es perfecto para el prototipo. Olvida todo al reiniciarse, lo cual está bien hasta que llega el despliegue. La regla del teléfono como thread_id no cambia cuando pasas a producción; lo único que cambia es el almacenamiento detrás del checkpointer. Los agentes de WhatsApp de código abierto que funcionan en producción usan exactamente este patrón, indexado por número de teléfono.
Por qué «usar ngrok y la Business API» falla primero
El camino habitual de los tutoriales arrastra un túnel local, plantillas de mensajes y una ventana de respuesta de 24 horas antes de que se ejecute cualquier lógica de IA. El camino de un solo webhook se salta los tres.
Es probable que primero recurras a la configuración estándar: un túnel de ngrok para que Meta pueda llegar a tu portátil, más la Business API oficial para enviar. Aquí es exactamente donde se rompe. La URL del túnel cambia en cada reinicio y se cae sin avisar, así que tu webhook deja de recibir en silencio mientras tu código parece estar bien. Y luego el lado del envío añade su propia fricción.
Con la API oficial de WhatsApp Business, cualquier mensaje que inicies fuera de una ventana de 24 horas debe ser una plantilla aprobada de antemano, y aproximadamente una de cada tres plantillas se rechaza en la primera revisión por problemas de formato o de categoría. Desde el 1 de julio de 2025, Meta también cobra por cada plantilla entregada, con precio según la categoría y el país, un modelo con varios costes ocultos para desarrolladores. Con Whapi.Cloud el agente responde con un texto libre mediante una sola llamada a la API, así que no hay cola de aprobación de plantillas ni facturación por plantilla que controlar. Ese es el argumento de previsibilidad de costes en una frase: una respuesta que puedes enviar libremente no se puede rechazar ni recargar.
| Lo que necesita la implementación | Un solo webhook de Whapi.Cloud | ngrok + Business API oficial |
|---|---|---|
| Recibir mensajes en local | URL de webhook alojada, sin túnel | Túnel de ngrok que rota las URL y se cae |
| Configuración de la cuenta | Escaneo de QR, activa en ~2 minutos | Verificación de empresa de Meta, de días a semanas |
| Enviar una respuesta | Texto libre, una llamada REST | Plantilla aprobada de antemano, ~1 de cada 3 rechazada |
| Plazos de respuesta | Sin ventana de servicio de 24 horas | Texto libre solo dentro de una ventana de 24 horas |
| Modelo de coste de envío | Suscripción, sin tarifa de plantilla por mensaje | Facturación por plantilla entregada desde julio de 2025 |
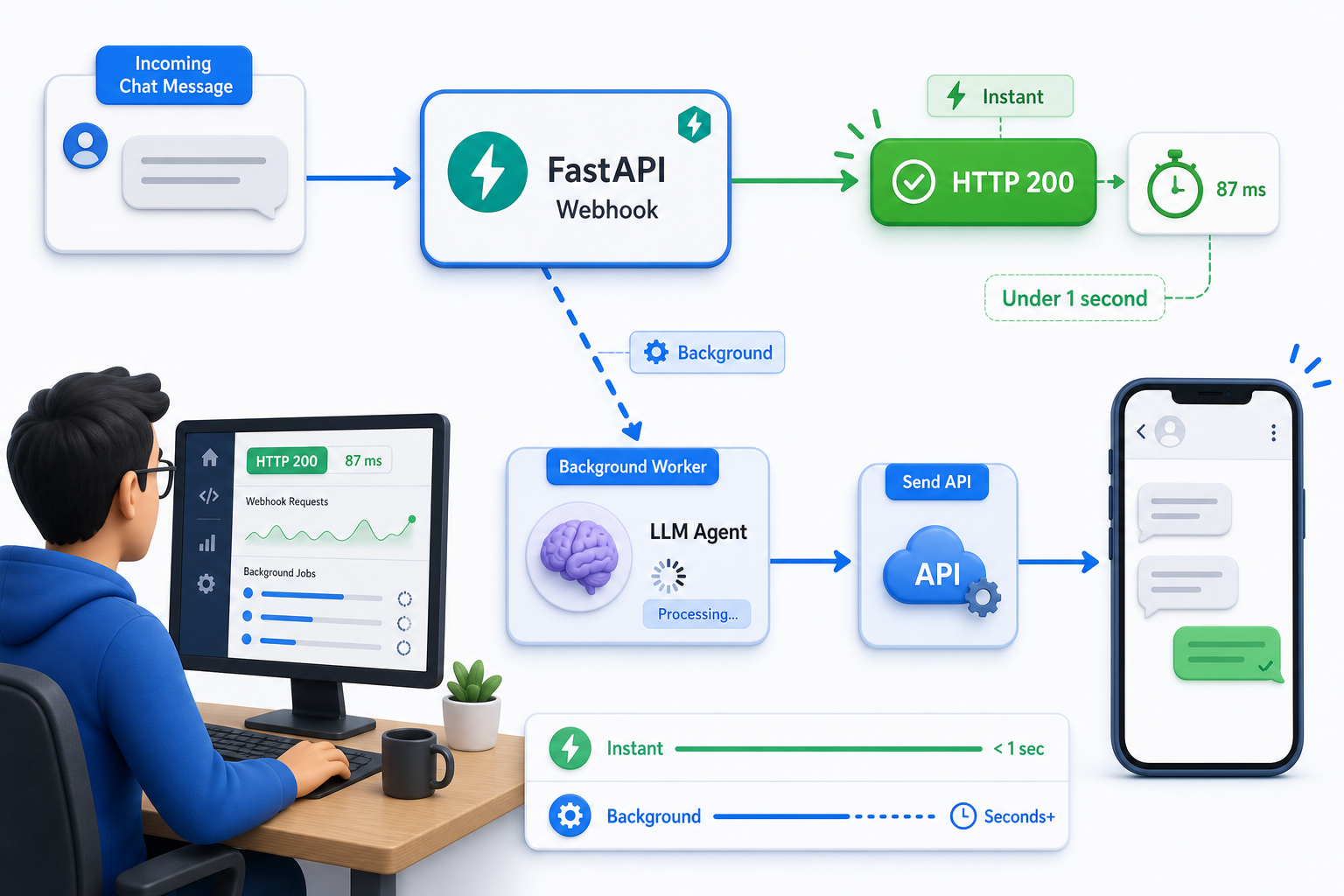
Devuelve un 200 rápido y ejecuta el agente en segundo plano
Confirma el webhook con un HTTP 200 de inmediato y luego ejecuta la lenta llamada al LLM en una tarea en segundo plano. Una respuesta lenta nunca debe mantener abierta la conexión del webhook.
Suscríbete solo al evento messages en la configuración del canal para que tu ruta no se active con las actualizaciones de estado ni los acuses de lectura. Cada payload de webhook entrante lleva el número del remitente, el tipo de mensaje y el cuerpo del texto; ignora todo lo que tenga from_me en verdadero para que el bot no responda a sus propios mensajes.
Una llamada al LLM tarda unos segundos; la confirmación de un webhook debería tardar milisegundos. Si tu manejador espera al agente antes de responder, la entrega puede agotar el tiempo y el mismo mensaje se vuelve a entregar, así que el usuario recibe la respuesta dos veces. BackgroundTasks de FastAPI te permite responder de inmediato y procesar después.
# webhook_async.py -- fast 200, then reason and reply in the background
import os, requests
from fastapi import FastAPI, Request, BackgroundTasks
app = FastAPI()
def handle(sender: str, text: str):
answer = reply_for(sender, text) # the slow part: agent + LLM
# POST https://gate.whapi.cloud/messages/text
# If you block the webhook waiting for this, Whapi retries the
# delivery and the contact gets the same answer twice.
requests.post(
"https://gate.whapi.cloud/messages/text",
headers={"Authorization": f"Bearer {os.environ['WHAPI_TOKEN']}"},
json={"to": sender, "body": answer},
timeout=30,
)
@app.post("/webhook")
async def webhook(request: Request, background: BackgroundTasks):
data = await request.json()
for msg in data.get("messages", []):
if msg.get("from_me"):
continue
background.add_task(handle, msg["from"], msg.get("text", {}).get("body", ""))
return {"status": "ok"} # returned in milliseconds
La respuesta se envía de vuelta mediante POST /messages/text con el número del remitente en el campo to y la respuesta del agente en body. Como la ruta responde antes de que el agente termine, las entregas siguen siendo rápidas y desaparecen los fallos de respuesta duplicada. El patrón que encontramos con más frecuencia en las primeras implementaciones rotas es un manejador síncrono que se bloquea esperando al modelo y, sin querer, enseña a la pasarela a reintentar.
Del prototipo a producción: cambia MemorySaver por Postgres
MemorySaver recuerda hasta el siguiente reinicio; un checkpointer de Postgres recuerda entre despliegues y caídas. El cambio es de una línea porque la regla del teléfono como thread_id se mantiene idéntica.
Despliega la app de FastAPI en cualquier host público para que la URL del webhook sea accesible, define WHAPI_TOKEN y la clave de tu modelo como variables de entorno y reemplaza MemorySaver por PostgresSaver. El estado de la conversación sobrevive entonces a los reinicios, y los mismos hilos por usuario siguen funcionando sin cambiar el código del agente.
Errores habituales de quienes lo crean por primera vez (y su solución)
Dos errores hacen tropezar a casi toda primera implementación: el envoltorio equivocado de OpenAI y una herramienta definida como método de clase. Ambos fallan al arrancar con mensajes confusos.
Si pasas el nombre de un modelo de chat como gpt-4o al antiguo envoltorio de completions, OpenAI devuelve This is a chat model and not supported in the v1/completions endpoint. La solución es usar ChatOpenAI, no la clase OpenAI de estilo completion.
# Wrong: completion wrapper rejects chat models
# from langchain_openai import OpenAI
# model = OpenAI(model="gpt-4o") # -> v1/completions endpoint error
# Right: chat model wrapper
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
El segundo error aparece cuando decoras un método de instancia con @tool. LangChain interpreta self como un argumento obligatorio de la herramienta y la construcción del agente falla. Define las herramientas como funciones a nivel de módulo y pasa cualquier estado compartido mediante un closure o un cliente global.
Si encuentras un comportamiento inesperado del lado de WhatsApp y no en tu Python, contacta con el equipo de soporte de Whapi.Cloud mediante el chat de whapi.cloud: el equipo ayuda activamente a los clientes a resolver problemas en producción. Aquí no cubriremos la transcripción de notas de voz ni la recuperación con vectores; ambas se apoyan en este mismo ciclo y merecen su propia guía.
Esa es toda la implementación: un webhook de Whapi.Cloud recibe, un agente de LangGraph razona con memoria indexada por el número de teléfono de cada persona y una sola llamada REST envía la respuesta. Saltarse los túneles, la verificación de Meta y la aprobación de plantillas es lo que la mantiene tan breve. Los equipos que automatizan la reserva de citas con este ciclo informan de que las ausencias caen una cuarta parte o más, y por eso vale la pena hacer bien el patrón de memoria por usuario. Conecta los tres pasos como se muestra y el agente mantiene una conversación real a lo largo de los mensajes.