Este guia passo a passo da Whapi.Cloud -- provedora de gateway de API para WhatsApp -- mostra como criar um chatbot de IA para WhatsApp pronto para produção com GPT-4o e Node.js. O WhatsApp não possui integração nativa com ChatGPT: não há nenhum botão, plugin oficial ou endpoint direto da OpenAI que você possa apontar para um número de telefone. Conectar o GPT-4o ao WhatsApp exige três componentes: um gateway de API que recebe as mensagens do WhatsApp e as entrega ao seu servidor, um servidor de webhooks que processa essas mensagens e uma camada de sessão que preserva o histórico da conversa entre turnos. Você pode criar, testar e implantar todo esse stack em menos de duas horas.
Este guia foi escrito para desenvolvedores e fundadores técnicos que constroem assistentes de IA para o WhatsApp. Não é um tutorial de cinco minutos -- é um passo a passo orientado à produção que abrange todo o pipeline de mensagens: configuração de webhooks, gerenciamento de estado de sessão, recuperação de erros, estimativa de custos e implantação HTTPS em um servidor real. Cada seção aborda um modo de falha que guias mais simples ignoram. Não cobre WhatsApp Flows, VoIP nem o processo de onboarding oficial do Meta BSP -- esses são temas separados.
O que a Maioria dos Tutoriais Erra sobre Chatbots de IA no WhatsApp
Um demo funcional não é um bot de produção. A maioria dos artigos sobre "criar um bot de WhatsApp com ChatGPT" para no conceito de webhook -- mostram como receber uma mensagem, chamar a API da OpenAI e enviar uma resposta. Isso funciona uma vez, de forma isolada, com uma única mensagem de teste. Quebra imediatamente quando há usuários reais.
Limites de taxa, gerenciamento de sessão e HTTPS são obrigatórios desde o primeiro dia. Veja o que costuma quebrar:
-
Chamadas ao GPT-4o sem estado: Sem gerenciamento de sessão, cada mensagem é uma conversa nova. O bot não tem memória de quem é o usuário nem do que foi dito dez segundos atrás. Não consegue dar continuidade, não referencia contexto e não constrói o fluxo conversacional que torna um assistente de IA útil.
-
Sem tratamento de erros: Se a chamada à OpenAI falhar ou expirar, o bot não envia nada. O usuário vê silêncio e assume que está quebrado -- porque, da perspectiva dele, está. Falhas silenciosas são indistinguíveis de bots offline.
-
ngrok em produção: O ngrok é uma ferramenta de desenvolvimento. Túneis caem sem aviso, URLs mudam a cada reinicialização e não há gerenciamento de processos. Quando o túnel cai, seu bot fica offline -- silenciosamente, sem alertas.
-
Chaves de API hardcoded: Credenciais no código-fonte acabam no histórico do git ou nos logs do servidor. Isso é uma falha de segurança, não uma preocupação para "corrigir depois".
O Pipeline Completo de Mensagens: WhatsApp → Whapi.Cloud → GPT-4o → WhatsApp
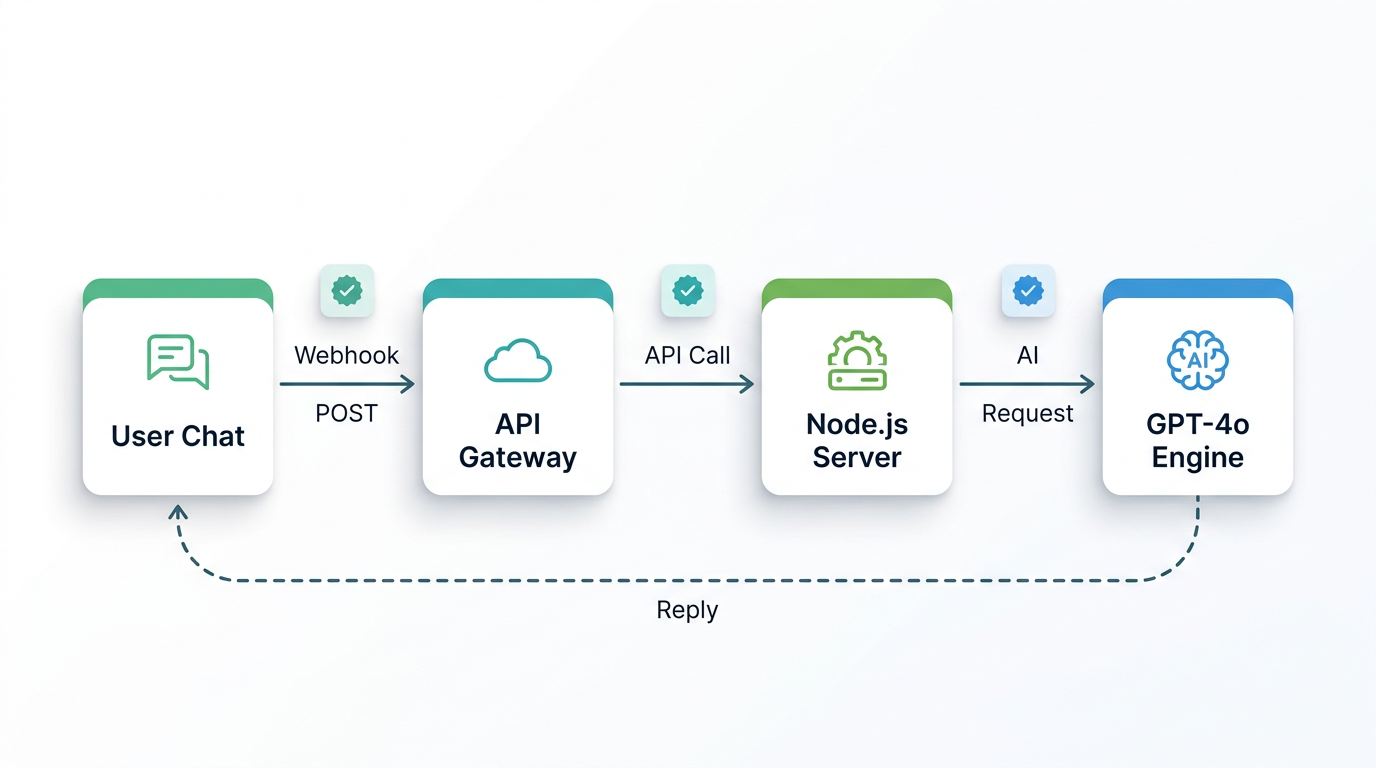
Entenda o pipeline antes de escrever uma única linha de código -- ele determina sua arquitetura. Cada mensagem que seu usuário envia percorre quatro saltos:
- WhatsApp → Whapi.Cloud: O usuário envia uma mensagem no WhatsApp. A Whapi.Cloud a recebe por meio da conexão de socket de sessão web -- o mesmo mecanismo que o WhatsApp Web usa -- e a entrega ao seu servidor como uma requisição HTTP POST.
- Whapi.Cloud → Seu servidor de webhooks: Seu servidor Node.js/Express recebe o payload do webhook. Extrai o ID do remetente e o texto da mensagem, depois encaminha a requisição para o seu handler de IA.
- Seu servidor → OpenAI GPT-4o: Seu servidor chama a API de Chat Completions da OpenAI com a mensagem do usuário mais todo o histórico da conversa. O GPT-4o retorna uma resposta.
- Seu servidor → Whapi.Cloud → WhatsApp: Seu servidor envia a resposta para o endpoint de envio de mensagens da Whapi.Cloud. A Whapi.Cloud a entrega ao WhatsApp do usuário.
Cada salto adiciona latência. O próprio GPT-4o leva de 1 a 3 segundos com carga padrão. A entrega pelo WhatsApp é quase instantânea. O tempo de resposta total percebido pelo usuário é tipicamente de 2 a 5 segundos -- defina essa expectativa no design do seu produto, não como desculpa após o lançamento. Para o formato completo do payload de entrada, consulte a referência de formato de webhooks de entrada.
Pré-requisitos: O Que Você Precisa Antes de Escrever uma Linha de Código
Você precisa de quatro coisas configuradas antes de começar:
-
Conta na Whapi.Cloud: Cadastre-se em panel.whapi.cloud/register. O plano gratuito é suficiente para desenvolvimento e testes.
-
Chave de API da OpenAI: Gere uma em platform.openai.com. O acesso ao GPT-4o está disponível no nível padrão da API com cobrança por uso.
-
Node.js v18+: Qualquer versão LTS moderna funciona. Você instalará quatro pacotes:
express,openai,axiosedotenv. -
ngrok (apenas para desenvolvimento): Expõe seu servidor local à internet para que a Whapi.Cloud possa entregar webhooks durante o desenvolvimento. Substitua por uma URL HTTPS real antes de ir para produção.
Passo 1 -- Obtenha Acesso à API do WhatsApp com a Whapi.Cloud (Sem Meta BSP)
A Whapi.Cloud fornece acesso a webhooks do WhatsApp sem necessidade de registro no Meta BSP. Você conecta um número do WhatsApp escaneando um QR code no painel -- o mesmo mecanismo que o WhatsApp Web usa -- e já pode enviar e receber mensagens em menos de um minuto. O caminho oficial da Meta exige registro BSP, aprovação prévia de templates e onboarding em múltiplas etapas -- um processo que leva dias ou semanas. A Whapi.Cloud elimina tudo isso: o usuário manda mensagem para o seu bot, o bot responde.
Para conectar seu número do WhatsApp e registrar seu webhook:
- Faça login no seu painel da Whapi.Cloud.
- Crie um novo canal. Dê um nome a ele (por exemplo, "Bot de Suporte com IA").
- Escaneie o QR code com a conta do WhatsApp que você quer usar como número do bot. A conexão é estabelecida imediatamente.
- Copie o token de API do seu canal -- você vai precisar dele no arquivo
.env. - Vá até a seção de Webhooks nas configurações do seu canal. Cole a URL HTTPS pública do seu servidor (ou a URL do ngrok durante o desenvolvimento), por exemplo:
https://yourdomain.com/webhook. Salve.
Assim que a URL do webhook for salva, a Whapi.Cloud encaminha todas as mensagens recebidas do WhatsApp para o seu servidor como requisições HTTP POST. Para detalhes completos de configuração, consulte o guia de início da Whapi.Cloud.
Passo 2 -- Construa o Servidor de Webhooks com Express
Comece pelas variáveis de ambiente. Nunca hardcode chaves de API. Use um arquivo .env e carregue-o com dotenv -- isso mantém as credenciais fora do código-fonte e fora do controle de versão:
# .env
OPENAI_API_KEY=sk-your-openai-key-here
WHAPI_TOKEN=your-whapi-cloud-token-here
WHAPI_API_URL=https://gate.whapi.cloud
PORT=3000
Instale os pacotes necessários:
npm init -y
npm install express openai axios dotenv
Agora crie o server.js -- o ponto de entrada que inicia o Express e define o endpoint do webhook:
// server.js -- Entry point: starts Express and defines the webhook endpoint
require('dotenv').config();
const express = require('express');
const { handleIncomingMessage } = require('./bot');
const app = express();
app.use(express.json());
// Whapi.Cloud delivers all incoming WhatsApp messages to this endpoint as HTTP POST
app.post('/webhook', async (req, res) => {
// Respond immediately -- Whapi.Cloud expects a fast 200 before processing
res.sendStatus(200);
const messages = req.body.messages;
if (!messages || messages.length === 0) return;
for (const message of messages) {
// Skip outbound messages echoed back by Whapi.Cloud -- prevents infinite reply loops
if (message.from_me) continue;
// This guide covers text messages only; other types (image, audio) require separate handling
if (message.type !== 'text') continue;
const senderId = message.from; // WhatsApp Chat ID of the sender
const userText = message.text.body; // The user's message text
await handleIncomingMessage(senderId, userText);
}
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => console.log(`Webhook server running on port ${PORT}`));
Duas decisões de implementação importantes aqui. Primeiro: responda com 200 OK imediatamente, antes de processar a mensagem. Se você processar de forma síncrona primeiro, respostas lentas do GPT-4o podem fazer a Whapi.Cloud tentar reenviar a entrega -- e você acaba processando a mesma mensagem duas vezes. Segundo: o filtro from_me não é opcional. A Whapi.Cloud espelha mensagens enviadas de volta para o seu webhook. Sem essa verificação, o bot responde às próprias mensagens em um loop infinito. Este guia trata mensagens de texto; a Whapi.Cloud também suporta os tipos imagem, áudio, documento e reação -- cada um entregue ao mesmo endpoint do webhook com um campo type diferente. Para uma referência de implementação mais ampla em Node.js, consulte o guia de bot WhatsApp com Node.js da Whapi.Cloud.
Passo 3 -- Conecte o GPT-4o ao Seu Handler de Webhooks
O módulo bot cuida de três tarefas: carregar o histórico da conversa do usuário, chamar o GPT-4o com esse histórico e enviar a resposta de volta pela API da Whapi.Cloud. A operação sendMessageText exige dois parâmetros: to (o ID de chat do WhatsApp do destinatário) e body (o texto da mensagem) -- ambos verificados no schema da API da Whapi.Cloud.
// bot.js -- GPT-4o integration and Whapi.Cloud message send-back
const OpenAI = require('openai');
const axios = require('axios');
const { getHistory, saveHistory } = require('./session');
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// System prompt defines the bot's persona, scope, and response style
// This is the most important configuration decision -- write it for your specific use case
const SYSTEM_PROMPT = {
role: 'system',
content: `You are a helpful AI assistant.
Keep replies concise -- WhatsApp users prefer short, clear messages.
If you cannot answer something, say so directly.`
};
// Calls GPT-4o with the full conversation history; returns the model's reply text
async function askGPT(history) {
const response = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [SYSTEM_PROMPT, ...history],
max_tokens: 500,
temperature: 0.7
});
return response.choices[0].message.content.trim();
}
// Sends a text reply to the user via Whapi.Cloud REST API
// Required params (verified via MCP): to (string), body (string)
async function sendWhatsAppMessage(to, body) {
await axios.post(
`${process.env.WHAPI_API_URL}/messages/text`,
{ to, body },
{ headers: { Authorization: `Bearer ${process.env.WHAPI_TOKEN}` } }
);
}
// Main handler: load history → call GPT-4o → save updated history → send reply
async function handleIncomingMessage(senderId, userText) {
try {
const history = await getHistory(senderId);
// Append the new user message to history
history.push({ role: 'user', content: userText });
// Truncate to last 20 messages -- controls token cost regardless of conversation length
const truncatedHistory = history.slice(-20);
// Call GPT-4o with the full conversation context
const reply = await askGPT(truncatedHistory);
// Append the assistant reply and persist the updated history
truncatedHistory.push({ role: 'assistant', content: reply });
await saveHistory(senderId, truncatedHistory);
// Deliver the reply to the user's WhatsApp
await sendWhatsAppMessage(senderId, reply);
} catch (error) {
console.error(`[${new Date().toISOString()}] Error for ${senderId}:`, error.message);
// Always send a fallback -- never leave the user with silence
await sendWhatsAppMessage(
senderId,
'I encountered an issue processing your request. Please try again in a moment.'
).catch(e => console.error('Failed to send fallback message:', e.message));
}
}
module.exports = { handleIncomingMessage };
O system prompt é a configuração mais importante do seu chatbot. Um prompt vago produz respostas fora do tema ou excessivamente longas -- especialmente prejudicial no WhatsApp, onde os usuários esperam respostas concisas. Escreva-o para o seu caso de uso específico: defina o escopo do assistente, o estilo de comunicação e o que ele deve dizer quando não consegue responder. Não trate isso como um placeholder.
Sem Estado de Sessão, o GPT-4o Trata Cada Mensagem do WhatsApp como uma Conversa Nova
O GPT-4o é stateless. Cada chamada à API é independente -- o modelo não tem memória de chamadas anteriores, a menos que você inclua explicitamente as mensagens anteriores no array messages. Sem uma camada de sessão, cada mensagem do WhatsApp enviada pelo usuário é tratada como o início de uma conversa nova. O bot não consegue dar continuidade, não referencia o que foi dito e produz uma experiência genuinamente confusa para usuários que esperam continuidade.
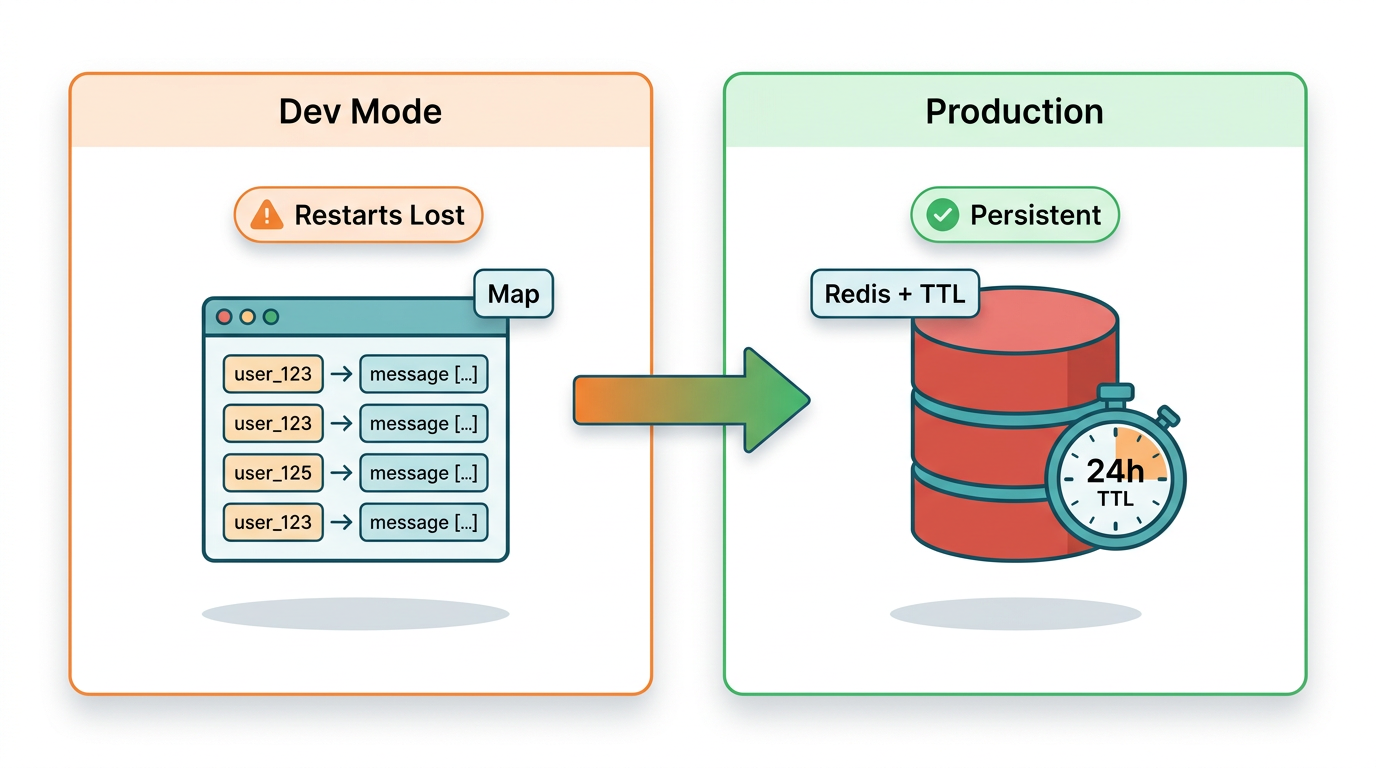
Nível 1 -- Map em Memória (Apenas para Desenvolvimento)
Para desenvolvimento local e testes rápidos, um Map JavaScript com chave pelo ID do remetente funciona sem nenhuma configuração:
// session-memory.js -- In-memory session store
// Inputs: senderId (string). Returns: history array (messages[]).
// WARNING: data is lost on every server restart. Use only in development.
const sessions = new Map();
function getHistory(senderId) {
if (!sessions.has(senderId)) {
sessions.set(senderId, []);
}
return Promise.resolve(sessions.get(senderId));
}
function saveHistory(senderId, history) {
sessions.set(senderId, history);
return Promise.resolve();
}
module.exports = { getHistory, saveHistory };
A limitação crítica: esses dados ficam na memória do processo. Uma reinicialização do servidor apaga todas as conversas. Com usuários simultâneos, você também corre o risco de crescimento ilimitado da memória sem política de expiração. Isso é aceitável para testes. Não é aceitável para produção.
Nível 2 -- Redis com TTL (Produção)
Redis com TTL é o armazenamento de sessão correto para bots WhatsApp em produção com usuários simultâneos. Sobrevive a reinicializações do servidor, lida com múltiplas instâncias sem conflitos e expira automaticamente sessões inativas -- alinhado com a própria janela de conversa de 24 horas do WhatsApp:
// session-redis.js -- Redis-backed session store for production
// Inputs: senderId (string), history array. Outputs: history array.
// TTL of 24 hours mirrors the WhatsApp session window -- sessions expire together.
const redis = require('redis');
const client = redis.createClient({ url: process.env.REDIS_URL || 'redis://localhost:6379' });
client.connect().catch(console.error);
const SESSION_TTL_SECONDS = 86400; // 24 hours
async function getHistory(senderId) {
const data = await client.get(`session:${senderId}`);
return data ? JSON.parse(data) : [];
}
async function saveHistory(senderId, history) {
await client.setEx(
`session:${senderId}`,
SESSION_TTL_SECONDS,
JSON.stringify(history)
);
}
module.exports = { getHistory, saveHistory };
Adicione o pacote redis (v4+) às suas dependências e defina a variável de ambiente REDIS_URL. Para trocar do armazenamento em memória para o Redis, mude uma linha no bot.js: require('./session-memory') vira require('./session-redis'). A interface é idêntica -- ambos os módulos exportam getHistory e saveHistory com a mesma assinatura.
| Abordagem | Persistência | Usuários simultâneos | Esforço de configuração | Recomendado para |
|---|---|---|---|---|
| Map em memória | Perdido ao reiniciar | Apenas instância única | Nenhum | Desenvolvimento local |
| Redis com TTL | Sobrevive a reinicializações | Seguro para múltiplas instâncias | Moderado | Produção |
Tratamento de Erros: Cada Falha Silenciosa do GPT-4o Deixa Seu Usuário sem Resposta
Todo bot WhatsApp em produção precisa de tratamento de erros. Isso não é opcional e não é uma "melhoria para a v2". Se sua chamada ao GPT-4o falhar -- por um timeout da OpenAI, um limite de taxa atingido ou um erro de rede -- e você não tiver um handler de erros, o usuário não recebe nada. Ele vai assumir que o bot está quebrado. Na maioria dos casos, estará certo.
O exemplo de bot.js acima inclui o try/catch básico com mensagem de fallback. Estenda-o com classificação de erros específica para que seus logs sejam acionáveis:
// Extended error classification inside handleIncomingMessage's catch block
} catch (error) {
const timestamp = new Date().toISOString();
if (error.status === 429) {
// OpenAI rate limit -- you have exceeded tokens-per-minute for this API key
// Consider queuing requests or implementing exponential backoff
console.warn(`[${timestamp}] OpenAI rate limit hit for ${senderId}. Status: 429`);
} else if (error.code === 'ECONNABORTED' || error.code === 'ETIMEDOUT') {
// OpenAI request took too long -- network issue or model overload
console.warn(`[${timestamp}] OpenAI request timed out for ${senderId}`);
} else {
// Unknown error -- log fully for investigation
console.error(`[${timestamp}] Unhandled error for ${senderId}:`, error.message);
}
// Send user-visible fallback regardless of error type
try {
await sendWhatsAppMessage(
senderId,
'I am having trouble right now. Please try again in a moment.'
);
} catch (sendError) {
// If even the fallback fails, the Whapi.Cloud connection itself is likely broken
console.error(`[${timestamp}] Fallback send failed for ${senderId}:`, sendError.message);
}
}
Sempre registre erros com timestamps e IDs do remetente. Entradas sem timestamps são praticamente inúteis em produção -- você não consegue correlacioná-las com relatos de usuários, incidentes de status da OpenAI ou logs de entrega da Whapi.Cloud. Se o envio do fallback também falhar, esse é um sinal separado: sua conexão com a Whapi.Cloud está quebrada, não apenas sua chamada à OpenAI. Trate esses dois tipos de falha como alertas distintos.
Sobre limites de taxa da OpenAI: HTTP 429 significa que você excedeu sua cota de tokens por minuto. A correção imediata é uma nova tentativa com backoff exponencial. A correção estrutural -- se isso se repetir -- é enfileirar as mensagens de entrada e processá-las com um limite de concorrência, em vez de disparar uma chamada ao GPT-4o para cada webhook simultaneamente.
Quanto Custa Rodar um Bot de IA no WhatsApp? Custo do GPT-4o por Mensagem
O GPT-4o custa aproximadamente $0,002--$0,005 por troca de mensagem média no WhatsApp com uso padrão de tokens. Essa estimativa considera uma mensagem típica do usuário de 20--50 tokens e uma resposta do modelo de 100--200 tokens, com um histórico de conversa de 10--15 turnos anteriores incluído em cada chamada à API. Nessa taxa, 10.000 trocas de mensagens custam aproximadamente $20--$50 por mês em taxas de API da OpenAI.
Os custos de tokens escalam diretamente com o tamanho do histórico. Truncar para 20 mensagens -- como no código acima -- mantém os custos por chamada previsíveis, independentemente do tamanho total da conversa. Você paga por 20 turnos de contexto por chamada, não importa há quanto tempo a conversa está acontecendo.
O GPT-4o custa mais por token do que o GPT-3.5-turbo, mas a diferença de qualidade é significativa para tarefas conversacionais abertas. Para respostas estruturadas e baseadas em templates onde o GPT-3.5-turbo é suficiente, trocar o modelo é uma mudança de uma linha: substitua 'gpt-4o' por 'gpt-3.5-turbo' na função askGPT. Analise seu uso real e a satisfação dos usuários antes de fazer o downgrade -- a otimização prematura aqui costuma aparecer como regressões de qualidade em tickets de suporte, não como números de benchmark.
A Whapi.Cloud usa preços baseados em assinatura sem taxas por mensagem próprias. Consulte os preços atuais dos planos da Whapi.Cloud para calcular o custo total do stack para o seu volume de mensagens.
Do ngrok para Produção: Implantando Seu Bot de IA do WhatsApp em um Servidor Real
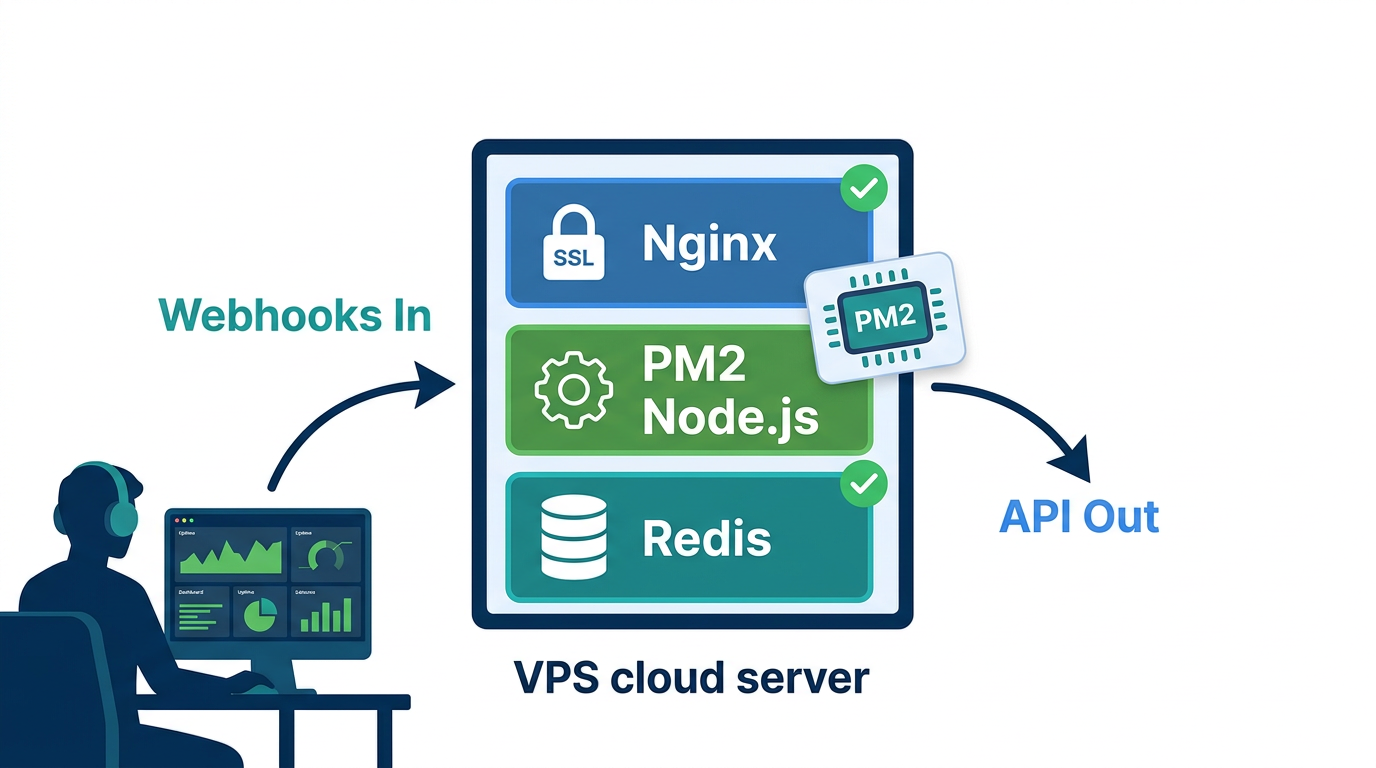
Rodar o ngrok em produção não é uma estratégia de implantação -- migre para um servidor real antes de compartilhar o bot com usuários reais. Qualquer VPS Linux com 1 GB de RAM suporta um bot de canal único em volume moderado de mensagens. Você precisa do Node.js instalado, Redis rodando e um domínio com certificado HTTPS válido. O WhatsApp bloqueia entregas de webhooks para URLs sem HTTPS. Não há alternativa.
Gerenciamento de Processos com PM2
O PM2 é o gerenciador de processos padrão para Node.js em produção. Reinicia seu servidor automaticamente após uma falha e após uma reinicialização do sistema:
# Install PM2 globally
npm install -g pm2
# Start the bot server under PM2 supervision
pm2 start server.js --name "whatsapp-ai-bot"
# Persist the PM2 process list across server reboots
pm2 save
# Generate and configure the system startup script
pm2 startup
Após executar pm2 startup, copie e execute o comando que ele gera -- isso registra o PM2 no processo de inicialização do seu sistema para que o bot reinicie automaticamente após uma reinicialização do servidor.
HTTPS com Nginx e Let's Encrypt
Use o Nginx como proxy reverso na frente do seu servidor Node.js. Seu app Express fica em http://localhost:3000 internamente. O Nginx termina o SSL e encaminha as requisições. Obtenha seu certificado do Let's Encrypt via Certbot:
# Install Nginx and Certbot (Ubuntu/Debian)
sudo apt update && sudo apt install nginx certbot python3-certbot-nginx -y
# Obtain and auto-configure an SSL certificate for your domain
sudo certbot --nginx -d yourdomain.com
# Certbot configures Nginx automatically and sets up certificate renewal
# Your webhook endpoint will be available at: https://yourdomain.com/webhook
Após executar o Certbot, atualize sua URL de webhook no painel da Whapi.Cloud para https://yourdomain.com/webhook. Use o recurso de teste de webhook no painel para verificar a entrega. Se os logs do seu servidor mostrarem o payload de teste chegando, a configuração de produção está funcionando.
Checklist de Prontidão para Produção
-
HTTPS habilitado com certificado válido (Let's Encrypt via Certbot)
-
PM2 rodando com persistência de inicialização configurada
-
Redis rodando com autenticação por senha, não exposto publicamente
-
Todos os segredos em variáveis de ambiente
.env-- não no código-fonte nem no histórico do git -
Tratamento de erros com mensagens de fallback visíveis ao usuário e logs do servidor com timestamps
-
Truncamento do histórico de mensagens para controlar custos de tokens em conversas longas
-
Filtro
from_meativo -- impede que o bot responda às próprias mensagens enviadas -
URL do webhook atualizada para o domínio HTTPS de produção no painel da Whapi.Cloud
-
Teste de webhook confirmado -- payload de teste recebido e registrado pelo seu servidor
Mais de 3.000 equipes usam a Whapi.Cloud em produção diariamente. As proteções de infraestrutura, incluindo proxies exclusivos e provedores regionais, cuidam da camada de conectividade. Sua responsabilidade é a camada de aplicação: estado de sessão, tratamento de erros e o system prompt que define o que seu bot realmente faz. Acerte esses pontos e você terá um bot pronto para ir ao ar. Para orientação sobre como operar seu número do WhatsApp com segurança em escala, consulte o guia da Whapi.Cloud para evitar banimentos de conta.
A Whapi.Cloud conecta seu número do WhatsApp ao seu servidor em menos de um minuto -- sem registro no Meta BSP, sem processo de aprovação de templates, sem período de espera. Escaneie um QR code, cole sua URL de webhook e comece a receber mensagens. A implementação que você precisa já está neste guia.