Esta guía paso a paso de Whapi.Cloud -- proveedor de gateway de API de WhatsApp -- explica cómo construir un chatbot de IA para WhatsApp listo para producción con GPT-4o y Node.js. WhatsApp no tiene integración nativa con ChatGPT: no hay ningún interruptor, ningún plugin oficial ni ningún endpoint directo de OpenAI que se pueda apuntar a un número de teléfono. Conectar GPT-4o a WhatsApp requiere tres componentes: un gateway de API que recibe los mensajes de WhatsApp y los envía a su servidor, un servidor de webhooks que procesa esos mensajes, y una capa de sesión que conserva el historial de conversación entre turnos. Puede construir, probar y desplegar este stack completo en menos de dos horas.
Esta guía está dirigida a desarrolladores y fundadores técnicos que construyen asistentes de IA para WhatsApp. No es un tutorial de cinco minutos: es un recorrido orientado a producción que cubre todo el pipeline de mensajes: configuración de webhooks, gestión del estado de sesión, recuperación de errores, estimación de costos y despliegue HTTPS en un servidor real. Cada sección aborda un modo de fallo que los tutoriales más simples omiten. No cubre WhatsApp Flows, VoIP ni el proceso de incorporación oficial de Meta BSP -- esos son temas separados.
Lo que la mayoría de los tutoriales omiten sobre los chatbots de IA para WhatsApp
Un demo funcional no es un bot de producción. La mayoría de los artículos sobre "crear un bot de WhatsApp con ChatGPT" se detienen en el concepto de webhook: muestran cómo recibir un mensaje, llamar a la API de OpenAI y enviar una respuesta. Eso funciona una vez, de forma aislada, con un único mensaje de prueba. Se rompe en cuanto hay usuarios reales.
Los límites de tasa, el manejo de sesiones y HTTPS son obligatorios desde el primer día. Esto es lo que suele fallar:
-
Llamadas a GPT-4o sin estado: Sin gestión de sesión, cada mensaje es una conversación nueva. El bot no tiene memoria de quién es el usuario ni de lo que se dijo diez segundos antes. No puede dar seguimiento, no puede referenciar el contexto y no puede construir el flujo conversacional que hace útil a un asistente de IA.
-
Sin manejo de errores: Si la llamada a OpenAI falla o se agota el tiempo, el bot no envía nada. El usuario ve silencio y asume que está roto -- porque desde su perspectiva, lo está. Los fallos silenciosos son indistinguibles de los bots desconectados.
-
ngrok en producción: Ngrok es una herramienta de desarrollo. Los túneles se cortan sin previo aviso, las URLs cambian al reiniciar y no hay gestión de procesos. Cuando el túnel cae, el bot se desconecta -- en silencio, sin alertas.
-
Claves API hardcodeadas: Las credenciales en el código fuente terminan en el historial de git o en los registros del servidor. Es un fallo de seguridad, no una preocupación para "arreglar después".
El pipeline completo de mensajes: WhatsApp → Whapi.Cloud → GPT-4o → WhatsApp
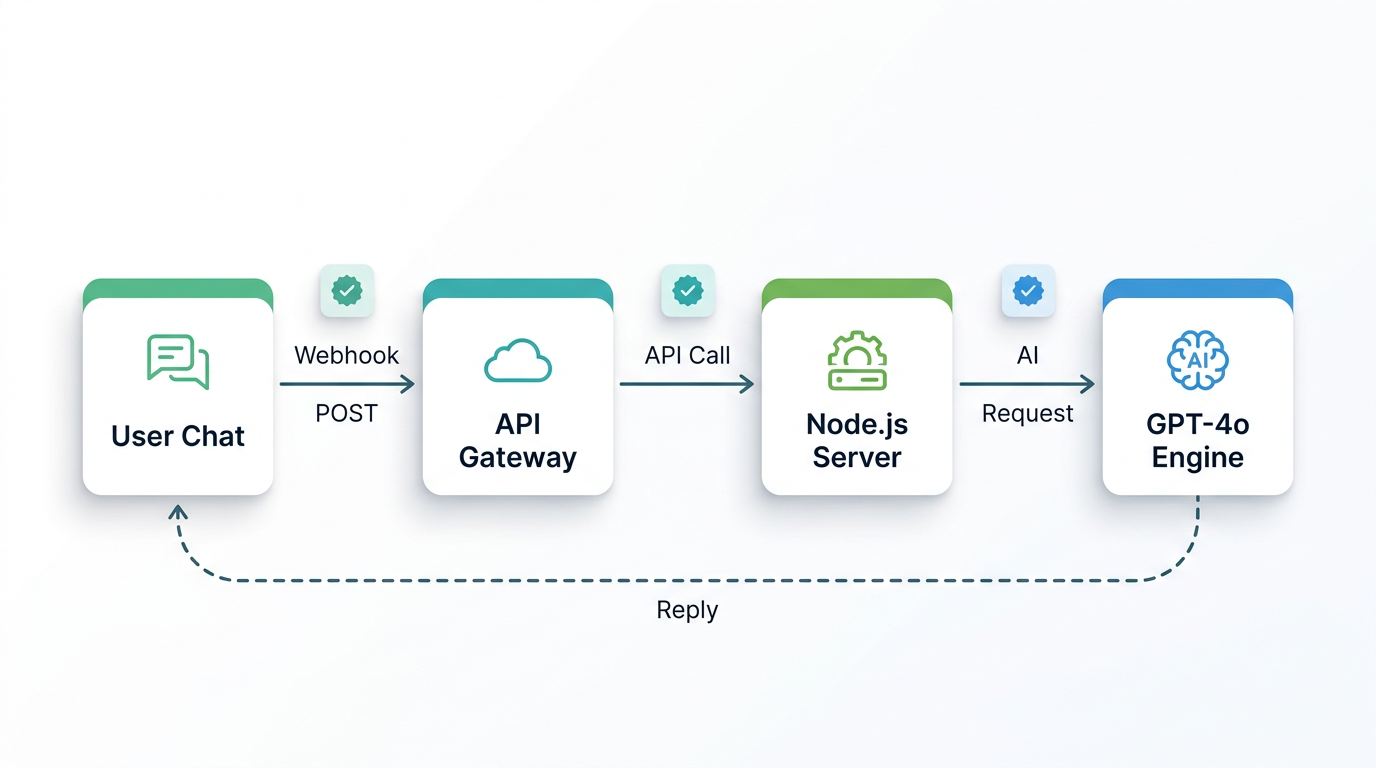
Comprenda el pipeline antes de escribir una sola línea de código -- determina su arquitectura. Cada mensaje que envía su usuario recorre cuatro saltos:
- WhatsApp → Whapi.Cloud: El usuario envía un mensaje de WhatsApp. Whapi.Cloud lo recibe a través de su conexión de socket de sesión web -- el mismo mecanismo que usa WhatsApp Web -- y lo entrega a su servidor como una solicitud HTTP POST.
- Whapi.Cloud → Su servidor de webhooks: Su servidor Node.js/Express recibe el payload del webhook. Extrae el ID del remitente y el texto del mensaje, luego enruta la solicitud a su manejador de IA.
- Su servidor → OpenAI GPT-4o: Su servidor llama a la API de Chat Completions de OpenAI con el mensaje del usuario más el historial completo de la conversación. GPT-4o devuelve una respuesta.
- Su servidor → Whapi.Cloud → WhatsApp: Su servidor envía la respuesta al endpoint de envío de mensajes de Whapi.Cloud. Whapi.Cloud la entrega al WhatsApp del usuario.
Cada salto agrega latencia. GPT-4o en sí toma 1--3 segundos con carga estándar. La entrega de WhatsApp es casi instantánea. El tiempo de respuesta total percibido por el usuario es típicamente de 2--5 segundos -- establezca esa expectativa en el diseño de su producto, no como una disculpa después del lanzamiento. Para el formato completo del payload entrante, consulte la referencia de formato de webhooks entrantes.
Requisitos previos: lo que necesita antes de escribir una línea de código
Necesita cuatro cosas configuradas antes de comenzar:
-
Cuenta en Whapi.Cloud: Regístrese en panel.whapi.cloud/register. El plan gratuito es suficiente para desarrollo y pruebas.
-
Clave API de OpenAI: Genere una en platform.openai.com. El acceso a GPT-4o está disponible en el nivel de API estándar con facturación por uso.
-
Node.js v18+: Cualquier versión LTS moderna funciona. Instalará cuatro paquetes:
express,openai,axiosydotenv. -
ngrok (solo desarrollo): Expone su servidor local a Internet para que Whapi.Cloud pueda entregar webhooks durante el desarrollo. Reemplácelo con una URL HTTPS real antes de pasar a producción.
Paso 1 -- Obtenga acceso a la API de WhatsApp con Whapi.Cloud (sin necesidad de Meta BSP)
Whapi.Cloud le da acceso a webhooks de WhatsApp sin necesidad de registro en Meta BSP. Conecta un número de WhatsApp escaneando un código QR en el panel -- el mismo mecanismo que usa WhatsApp Web -- y estará listo para enviar y recibir mensajes en menos de un minuto. La ruta oficial de Meta requiere registro BSP, aprobación previa de plantillas e incorporación en varios pasos -- un proceso que lleva días o semanas. Whapi.Cloud omite todo eso: el usuario le escribe a su bot, su bot responde.
Para conectar su número de WhatsApp y registrar su webhook:
- Inicie sesión en su panel de Whapi.Cloud.
- Cree un nuevo canal. Asígnele un nombre (por ejemplo, "Bot de soporte con IA").
- Escanee el código QR con la cuenta de WhatsApp que desea usar como número del bot. La conexión se establece de inmediato.
- Copie el token API de su canal -- lo necesitará en su archivo
.env. - Vaya a la sección de Webhooks en la configuración de su canal. Pegue la URL HTTPS pública de su servidor (o la URL de ngrok durante el desarrollo), por ejemplo:
https://yourdomain.com/webhook. Guarde.
Una vez guardada la URL del webhook, Whapi.Cloud reenvía todos los mensajes entrantes de WhatsApp a su servidor como solicitudes HTTP POST. Para obtener detalles completos de configuración, consulte la guía de inicio de Whapi.Cloud.
Paso 2 -- Construya el servidor de webhooks con Express
Comience con sus variables de entorno. Nunca hardcodee claves API. Use un archivo .env y cárguelo con dotenv -- esto mantiene las credenciales fuera del código fuente y fuera del control de versiones:
# .env
OPENAI_API_KEY=sk-your-openai-key-here
WHAPI_TOKEN=your-whapi-cloud-token-here
WHAPI_API_URL=https://gate.whapi.cloud
PORT=3000
Instale los paquetes necesarios:
npm init -y
npm install express openai axios dotenv
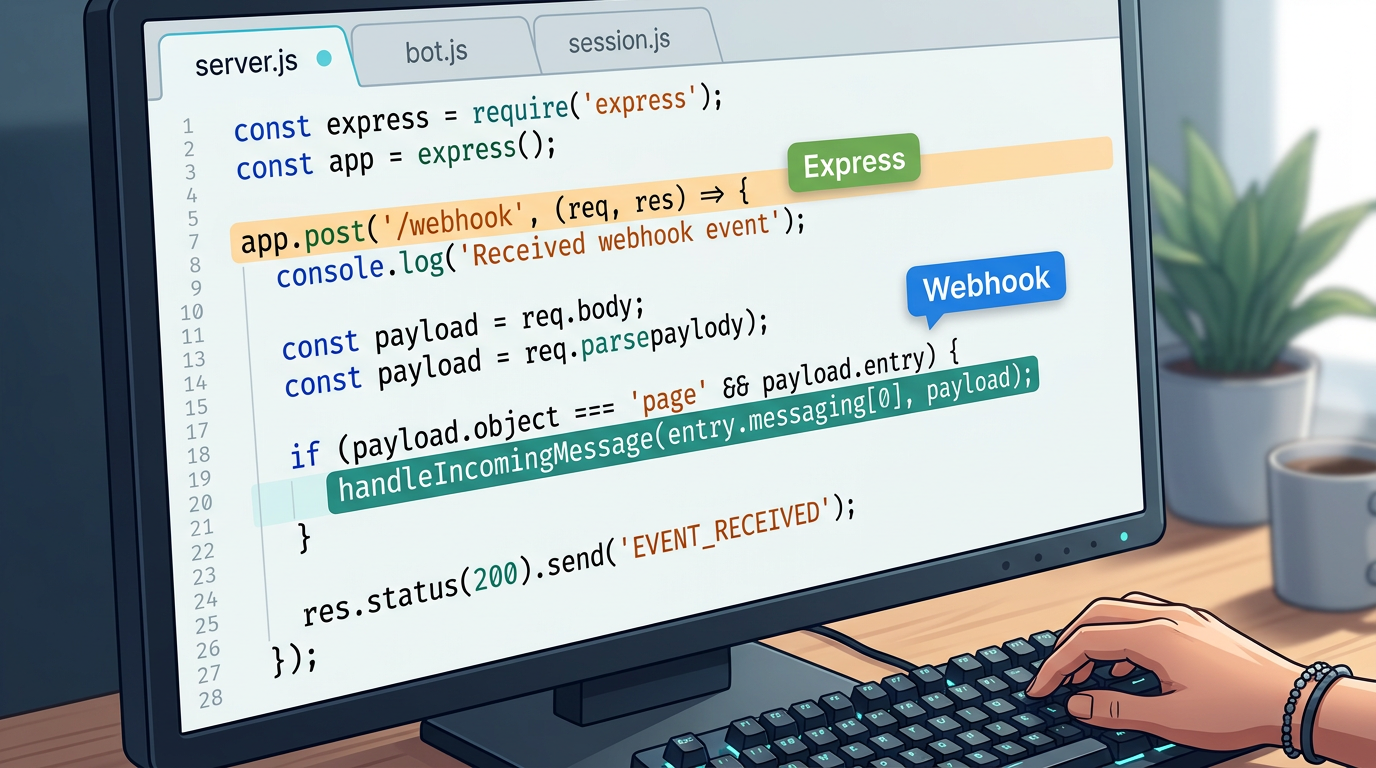
Ahora cree server.js -- el punto de entrada que inicia Express y define el endpoint del webhook:
// server.js -- Entry point: starts Express and defines the webhook endpoint
require('dotenv').config();
const express = require('express');
const { handleIncomingMessage } = require('./bot');
const app = express();
app.use(express.json());
// Whapi.Cloud delivers all incoming WhatsApp messages to this endpoint as HTTP POST
app.post('/webhook', async (req, res) => {
// Respond immediately -- Whapi.Cloud expects a fast 200 before processing
res.sendStatus(200);
const messages = req.body.messages;
if (!messages || messages.length === 0) return;
for (const message of messages) {
// Skip outbound messages echoed back by Whapi.Cloud -- prevents infinite reply loops
if (message.from_me) continue;
// This guide covers text messages only; other types (image, audio) require separate handling
if (message.type !== 'text') continue;
const senderId = message.from; // WhatsApp Chat ID of the sender
const userText = message.text.body; // The user's message text
await handleIncomingMessage(senderId, userText);
}
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => console.log(`Webhook server running on port ${PORT}`));
Dos decisiones de implementación importantes aquí. Primero: responda con 200 OK de inmediato, antes de procesar el mensaje. Si procesa de forma sincrónica primero, las respuestas lentas de GPT-4o pueden hacer que Whapi.Cloud reintente la entrega -- y terminará procesando el mismo mensaje dos veces. Segundo: el filtro from_me no es opcional. Whapi.Cloud refleja los mensajes salientes de vuelta a su webhook. Sin esta comprobación, el bot responde a sus propios mensajes en un bucle infinito. Esta guía maneja mensajes de texto; Whapi.Cloud también admite tipos de imagen, audio, documento y reacción -- cada uno entregado al mismo endpoint del webhook con un campo type diferente. Para una referencia de implementación más amplia en Node.js, consulte la guía de bot de WhatsApp con Node.js de Whapi.Cloud.
Paso 3 -- Conecte GPT-4o a su manejador de webhooks
El módulo bot maneja tres tareas: cargar el historial de conversación del usuario, llamar a GPT-4o con ese historial y enviar la respuesta de vuelta a través de la API de Whapi.Cloud. La operación sendMessageText requiere dos parámetros: to (el ID de chat de WhatsApp del destinatario) y body (el texto del mensaje) -- ambos verificados contra el esquema de la API de Whapi.Cloud.
// bot.js -- GPT-4o integration and Whapi.Cloud message send-back
const OpenAI = require('openai');
const axios = require('axios');
const { getHistory, saveHistory } = require('./session');
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// System prompt defines the bot's persona, scope, and response style
// This is the most important configuration decision -- write it for your specific use case
const SYSTEM_PROMPT = {
role: 'system',
content: `You are a helpful AI assistant.
Keep replies concise -- WhatsApp users prefer short, clear messages.
If you cannot answer something, say so directly.`
};
// Calls GPT-4o with the full conversation history; returns the model's reply text
async function askGPT(history) {
const response = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [SYSTEM_PROMPT, ...history],
max_tokens: 500,
temperature: 0.7
});
return response.choices[0].message.content.trim();
}
// Sends a text reply to the user via Whapi.Cloud REST API
// Required params (verified via MCP): to (string), body (string)
async function sendWhatsAppMessage(to, body) {
await axios.post(
`${process.env.WHAPI_API_URL}/messages/text`,
{ to, body },
{ headers: { Authorization: `Bearer ${process.env.WHAPI_TOKEN}` } }
);
}
// Main handler: load history → call GPT-4o → save updated history → send reply
async function handleIncomingMessage(senderId, userText) {
try {
const history = await getHistory(senderId);
// Append the new user message to history
history.push({ role: 'user', content: userText });
// Truncate to last 20 messages -- controls token cost regardless of conversation length
const truncatedHistory = history.slice(-20);
// Call GPT-4o with the full conversation context
const reply = await askGPT(truncatedHistory);
// Append the assistant reply and persist the updated history
truncatedHistory.push({ role: 'assistant', content: reply });
await saveHistory(senderId, truncatedHistory);
// Deliver the reply to the user's WhatsApp
await sendWhatsAppMessage(senderId, reply);
} catch (error) {
console.error(`[${new Date().toISOString()}] Error for ${senderId}:`, error.message);
// Always send a fallback -- never leave the user with silence
await sendWhatsAppMessage(
senderId,
'I encountered an issue processing your request. Please try again in a moment.'
).catch(e => console.error('Failed to send fallback message:', e.message));
}
}
module.exports = { handleIncomingMessage };
El prompt de sistema es la configuración más importante de su chatbot. Un prompt vago produce respuestas fuera de tema o excesivamente largas -- especialmente dañino en WhatsApp, donde los usuarios esperan respuestas concisas. Escríbalo para su caso de uso exacto: defina el alcance del asistente, el estilo de comunicación y lo que debe decir cuando no puede responder. No lo trate como un marcador de posición.
Sin estado de sesión, GPT-4o trata cada mensaje de WhatsApp como una conversación nueva
GPT-4o no tiene estado. Cada llamada a la API es independiente -- el modelo no tiene memoria de llamadas anteriores a menos que incluya explícitamente los mensajes previos en el arreglo messages. Sin una capa de sesión, cada mensaje de WhatsApp que envíe el usuario se trata como el inicio de una conversación nueva. El bot no puede dar seguimiento, no puede referenciar lo que se dijo, y produce una experiencia genuinamente desorientadora para los usuarios que esperan continuidad.
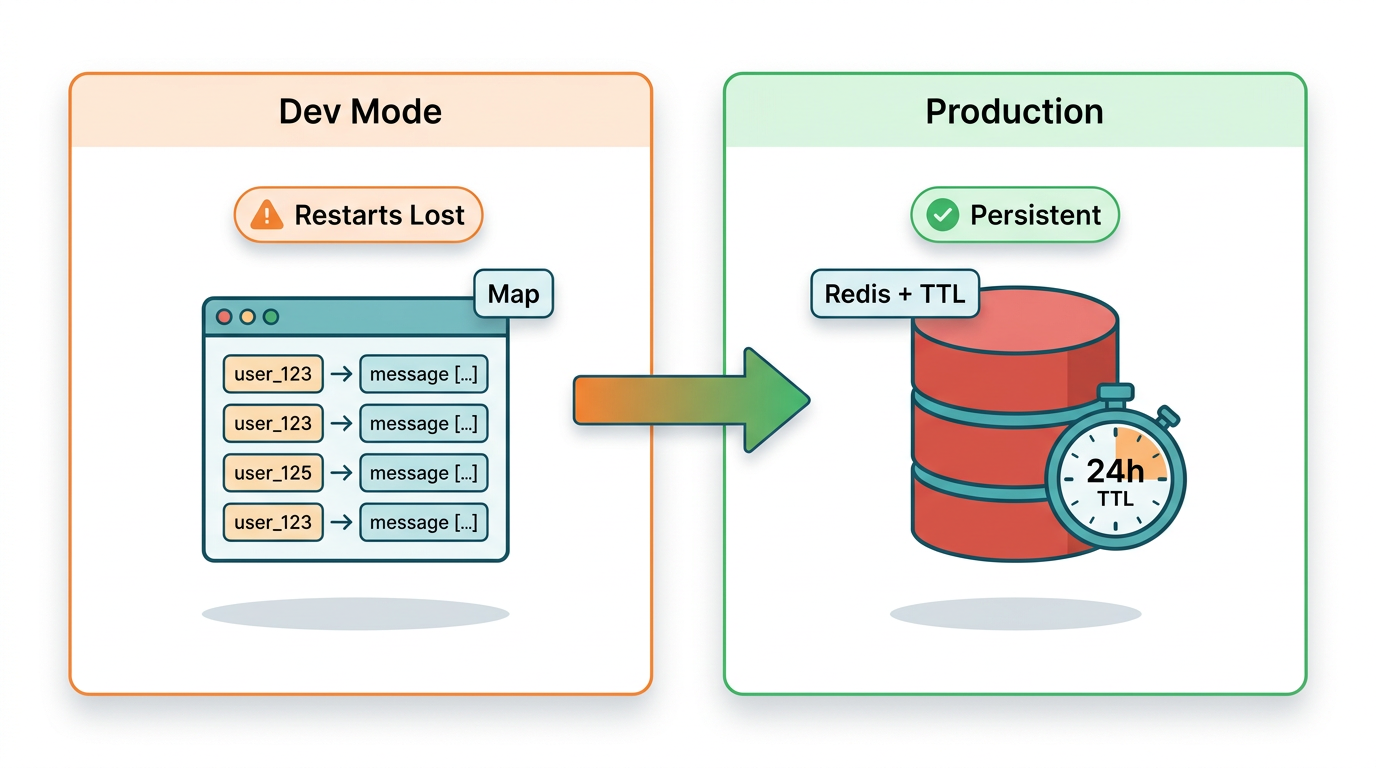
Nivel 1 -- Map en memoria (solo desarrollo)
Para desarrollo local y pruebas rápidas, un Map de JavaScript con clave por ID de remitente funciona sin ninguna configuración:
// session-memory.js -- In-memory session store
// Inputs: senderId (string). Returns: history array (messages[]).
// WARNING: data is lost on every server restart. Use only in development.
const sessions = new Map();
function getHistory(senderId) {
if (!sessions.has(senderId)) {
sessions.set(senderId, []);
}
return Promise.resolve(sessions.get(senderId));
}
function saveHistory(senderId, history) {
sessions.set(senderId, history);
return Promise.resolve();
}
module.exports = { getHistory, saveHistory };
La limitación crítica: estos datos viven en la memoria del proceso. Un reinicio del servidor borra todas las conversaciones. Con usuarios concurrentes, también se corre el riesgo de un crecimiento ilimitado de la memoria sin política de desalojo. Esto es aceptable para pruebas. No es aceptable para producción.
Nivel 2 -- Redis con TTL (producción)
Redis con TTL es el almacén de sesiones correcto para bots de WhatsApp en producción con usuarios concurrentes. Sobrevive a los reinicios del servidor, maneja múltiples instancias de aplicación sin conflictos y expira automáticamente las sesiones inactivas -- alineado con la propia ventana de conversación de 24 horas de WhatsApp:
// session-redis.js -- Redis-backed session store for production
// Inputs: senderId (string), history array. Outputs: history array.
// TTL of 24 hours mirrors the WhatsApp session window -- sessions expire together.
const redis = require('redis');
const client = redis.createClient({ url: process.env.REDIS_URL || 'redis://localhost:6379' });
client.connect().catch(console.error);
const SESSION_TTL_SECONDS = 86400; // 24 hours
async function getHistory(senderId) {
const data = await client.get(`session:${senderId}`);
return data ? JSON.parse(data) : [];
}
async function saveHistory(senderId, history) {
await client.setEx(
`session:${senderId}`,
SESSION_TTL_SECONDS,
JSON.stringify(history)
);
}
module.exports = { getHistory, saveHistory };
Agregue el paquete redis (v4+) a sus dependencias y configure una variable de entorno REDIS_URL. Para cambiar del almacén en memoria a Redis, cambie una línea en bot.js: require('./session-memory') se convierte en require('./session-redis'). La interfaz es idéntica -- ambos módulos exportan getHistory y saveHistory con la misma firma.
| Enfoque | Persistencia | Usuarios concurrentes | Esfuerzo de configuración | Recomendado para |
|---|---|---|---|---|
| Map en memoria | Se pierde al reiniciar | Solo instancia única | Ninguno | Desarrollo local |
| Redis con TTL | Sobrevive a reinicios | Seguro para múltiples instancias | Moderado | Producción |
Manejo de errores: cada fallo silencioso de GPT-4o deja a su usuario sin respuesta
Todo bot de WhatsApp en producción necesita manejo de errores. Esto no es opcional ni una "mejora para la v2". Si su llamada a GPT-4o falla -- por un timeout de OpenAI, un límite de tasa alcanzado o un error de red -- y no tiene un manejador de errores, el usuario no recibe nada. Asumirá que el bot está roto. En la mayoría de los casos, tendrá razón.
El ejemplo de bot.js anterior incluye el try/catch básico con un mensaje de respaldo. Amplíelo con clasificación de errores específica para que sus registros sean accionables:
// Extended error classification inside handleIncomingMessage's catch block
} catch (error) {
const timestamp = new Date().toISOString();
if (error.status === 429) {
// OpenAI rate limit -- you have exceeded tokens-per-minute for this API key
// Consider queuing requests or implementing exponential backoff
console.warn(`[${timestamp}] OpenAI rate limit hit for ${senderId}. Status: 429`);
} else if (error.code === 'ECONNABORTED' || error.code === 'ETIMEDOUT') {
// OpenAI request took too long -- network issue or model overload
console.warn(`[${timestamp}] OpenAI request timed out for ${senderId}`);
} else {
// Unknown error -- log fully for investigation
console.error(`[${timestamp}] Unhandled error for ${senderId}:`, error.message);
}
// Send user-visible fallback regardless of error type
try {
await sendWhatsAppMessage(
senderId,
'I am having trouble right now. Please try again in a moment.'
);
} catch (sendError) {
// If even the fallback fails, the Whapi.Cloud connection itself is likely broken
console.error(`[${timestamp}] Fallback send failed for ${senderId}:`, sendError.message);
}
}
Siempre registre los errores con marcas de tiempo e IDs de remitente. Las entradas sin marcas de tiempo son prácticamente inútiles en producción -- no puede correlacionarlas con informes de usuarios, incidentes de estado de OpenAI ni registros de entrega de Whapi.Cloud. Si el envío del mensaje de respaldo también falla, esa es una señal separada: su conexión con Whapi.Cloud está rota, no solo su llamada a OpenAI. Trate estos dos tipos de fallo como alertas distintas.
Sobre los límites de tasa de OpenAI: HTTP 429 significa que ha superado su asignación de tokens por minuto. La solución inmediata es un reintento con backoff exponencial. La solución estructural -- si esto se repite -- es encolar los mensajes entrantes y procesarlos con un límite de concurrencia, en lugar de disparar una llamada a GPT-4o por cada webhook simultáneamente.
¿Cuánto cuesta operar un bot de IA de WhatsApp? Costo de GPT-4o por mensaje
GPT-4o cuesta aproximadamente $0.002--$0.005 por intercambio de mensajes promedio de WhatsApp con el uso estándar de tokens. Esta estimación asume un mensaje típico del usuario de 20--50 tokens y una respuesta del modelo de 100--200 tokens, con un historial de conversación de 10--15 turnos previos incluido en cada llamada a la API. A estas tarifas, 10,000 intercambios de mensajes cuestan aproximadamente $20--$50 al mes en tarifas de la API de OpenAI.
Los costos de tokens escalan directamente con la longitud del historial. Truncar a 20 mensajes -- como en el código anterior -- mantiene los costos por llamada predecibles independientemente de la longitud total de la conversación. Paga por 20 turnos de contexto por llamada, sin importar cuánto tiempo lleve la conversación.
GPT-4o cuesta más por token que GPT-3.5-turbo, pero la diferencia de calidad es significativa para tareas conversacionales abiertas. Para respuestas estructuradas y de tipo plantilla donde GPT-3.5-turbo es suficiente, cambiar el modelo es un cambio de una sola línea: reemplace 'gpt-4o' con 'gpt-3.5-turbo' en la función askGPT. Analice su uso real y la satisfacción del usuario antes de degradar el modelo -- la optimización prematura aquí suele aparecer como regresiones de calidad en los tickets de soporte, no como números de referencia.
Whapi.Cloud utiliza precios basados en suscripción sin tarifas por mensaje propias. Consulte los precios actuales de los planes de Whapi.Cloud para calcular el costo total del stack según su volumen de mensajes.
De ngrok a producción: cómo desplegar su bot de IA de WhatsApp en un servidor real
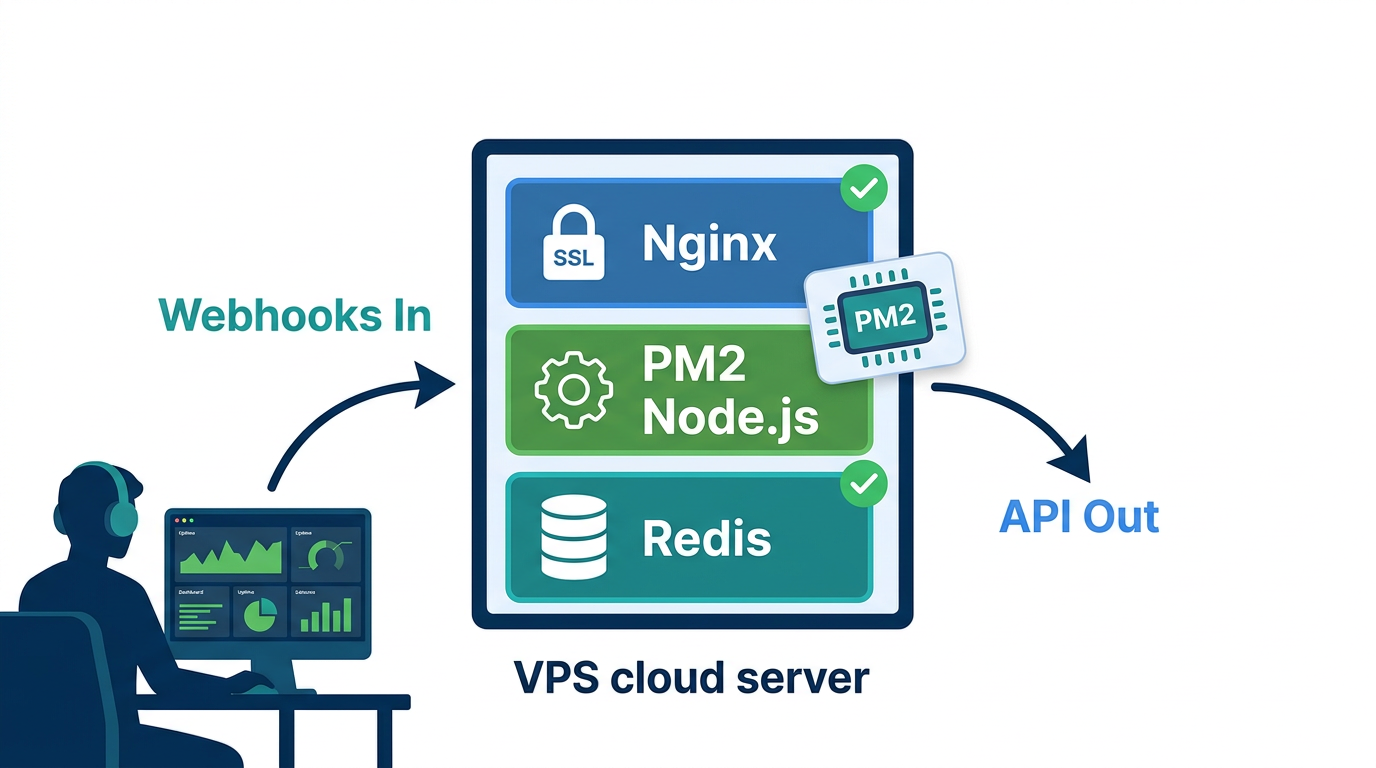
Ejecutar ngrok en producción no es una estrategia de despliegue -- pase a un servidor real antes de compartir el bot con usuarios reales. Cualquier VPS Linux con 1 GB de RAM maneja un bot de canal único a un volumen moderado de mensajes. Necesita Node.js instalado, Redis en ejecución y un nombre de dominio con un certificado HTTPS válido. WhatsApp bloquea las entregas de webhooks a URLs que no sean HTTPS. No hay solución alternativa.
Gestión de procesos con PM2
PM2 es el gestor de procesos estándar para Node.js en producción. Reinicia su servidor automáticamente tras un fallo y tras un reinicio del sistema:
# Install PM2 globally
npm install -g pm2
# Start the bot server under PM2 supervision
pm2 start server.js --name "whatsapp-ai-bot"
# Persist the PM2 process list across server reboots
pm2 save
# Generate and configure the system startup script
pm2 startup
Después de ejecutar pm2 startup, copie y ejecute el comando que genera -- esto registra PM2 con el proceso de inicio de su sistema para que el bot se reinicie automáticamente tras un reinicio del servidor.
HTTPS con Nginx y Let's Encrypt
Use Nginx como proxy inverso frente a su servidor Node.js. Su aplicación Express se mantiene en http://localhost:3000 internamente. Nginx termina SSL y reenvía las solicitudes. Obtenga su certificado de Let's Encrypt a través de Certbot:
# Install Nginx and Certbot (Ubuntu/Debian)
sudo apt update && sudo apt install nginx certbot python3-certbot-nginx -y
# Obtain and auto-configure an SSL certificate for your domain
sudo certbot --nginx -d yourdomain.com
# Certbot configures Nginx automatically and sets up certificate renewal
# Your webhook endpoint will be available at: https://yourdomain.com/webhook
Después de ejecutar Certbot, actualice su URL de webhook en el panel de Whapi.Cloud a https://yourdomain.com/webhook. Use la función de prueba de webhooks en el panel para verificar la entrega. Si los registros de su servidor muestran que llega el payload de prueba, la configuración de producción está funcionando.
Lista de verificación para producción
-
HTTPS habilitado con un certificado válido (Let's Encrypt mediante Certbot)
-
PM2 en ejecución con persistencia de inicio configurada
-
Redis en ejecución con autenticación por contraseña, no expuesto públicamente
-
Todos los secretos en variables de entorno
.env-- no en el código fuente ni en el historial de git -
Manejo de errores con mensajes de respaldo visibles al usuario y registro del lado del servidor con marcas de tiempo
-
Truncamiento del historial de mensajes para controlar los costos de tokens en conversaciones largas
-
Filtro
from_meactivo -- evita que el bot responda a sus propios mensajes salientes -
URL del webhook actualizada al dominio HTTPS de producción en el panel de Whapi.Cloud
-
Prueba de webhook confirmada -- payload de prueba recibido y registrado por su servidor
Más de 3,000 equipos usan Whapi.Cloud en producción a diario. Las protecciones de infraestructura, incluyendo proxies únicos y proveedores regionales, gestionan la capa de conectividad. Su responsabilidad es la capa de aplicación: el estado de sesión, el manejo de errores y el prompt de sistema que define lo que su bot realmente hace. Haga esto bien y tendrá un bot que vale la pena lanzar. Para orientación sobre cómo operar su número de WhatsApp de forma segura a escala, consulte la guía de Whapi.Cloud para evitar bloqueos de cuenta.
Whapi.Cloud conecta su número de WhatsApp a su servidor en menos de un minuto -- sin registro en Meta BSP, sin proceso de aprobación de plantillas, sin períodos de espera. Escanee un código QR, pegue su URL de webhook y empiece a recibir mensajes. La implementación que necesita ya está en esta guía.